- 一、Redis系统介绍
- 二、Redis核心概念与体系结构
- 三、Redis数据类型
- 四、Redis事务处理(Redis Transactions)
- 五、发布-订阅系统(Publish/Subscribe System)
- 六、Streams
- 七、Redis序列化协议(REdis Serialization Protocol)
- 八、Redis单节点体系结构(Single Node Architecture)
- 九、数据持久化 (Data Persistence)
- 十、数据复制(Data Replication)
- 十一、高可用性(High Availability)和哨兵(Sentinel)机制
- 十二、Redis集群(Redis Cluster)
- 十三、Redis编程-Java篇
- 十四、Redis编程-Python篇
- 十五、小测验
第六章 Streams
1 概述
Redis在5.0版本中加入了一个新的数据类型: Streams。 从概念上来看,Streams是一个简单的线性结构。它将所有的记录按照顺序排列在链表中。开发人员可以向Streams添加新的记录,也可以以多种方式查询Streams内的记录。但是,从实现和使用方式上来看,Streams是一个非常复杂的数据结构,原因有三: (1)Streams提供了类似于发布-订阅模式的操作方式。当有新元素加入之后,所有的客户端(或者消费者Consumer)都能收到一份新元素。客户端之间是相互独立的; (2) Streams支持非阻塞(Non-Blocking)和阻塞(Blocking)两种工作方式。在非阻塞模式下,无论是否能从Streams中读取一个元素,该读取操作都会立即返回。在阻塞模式下,如果读取操作不能获取新元素的话,该读取操作会被阻塞,直到有新元素加入Streams为止(或者超时); (3) Streams还支持消费者组(Consumer Group)的概念;由消费者组中的消费者共同读取新元素。
正是因为Streams数据结构的复杂性,我们并没有将其与其他数据类型放在一个章节中。而且,Streams的使用方法与Redis发布-订阅系统有相似之处,所以,我们在介绍了发布-订阅系统之后,我们再来单独讲解Streams,以帮助读者清晰的比较两者的不同。我们将它们之间显著的区别总结如下。
- 数据读取方式不同: 在发布-订阅模式下,客户端在订阅频道之后,不能继续执行与发布-订阅无关的命令。此时,客户端处于等待内容的状态。使用Streams时,客户端使用命令XREAD或者XRANGE查询Streams中的内容。使用这些命令既可以查询新数据,也可以查询历史数据。
- 数据获取的时间不同: 在发布-订阅模式下,当有新数据发布时,订阅者立即收到新的数据。而在使用Streams时,客户端可根据自身情况,使用命令获取数据。Streams会为每个客户端独立管理客户端的状态。
- 数据存放时间不同: 在发布-订阅模式下,当数据发送至客户端后,Redis不再保存这些数据。而Streams则会保存所有的数据。当开启了数据持久化功能之后,这些数据也会持久化。
- 数据处理的方式不同: 与发布-订阅模式相同的是,Streams也支持"多播(Multicasting)"模式,即当有新数据生成时,每一个客户端都会收到一份数据拷贝。但是,不同之处在于,Streams还支持消费者组; 消费者组中的消费者共同处理新的数据。假如一个消费者组里有两位消费者,在此时,如果有两条新生成的数据,那么,一种可能的情况是,第一位消费者接收并处理第一条数据,第二位消费者接收并处理第二条消息。
我们将在如下的章节中依次介绍Streams的基本概念、用法和与其相关的内容。
2 Streams的内部结构
在Redis内部,Streams数据结构包含几个部件。首先,向Streams添加的数据全部保存在一个链表中。链表中每一个节点表示的是一个相互独立的数据。这些数据有着唯一的一个ID,被称为Entry ID。它们在所在的Stream的内部是唯一的,单调递增的。因此,客户端或者消费者能够根据Entry ID的范围查询对应的数据。
当向Stream添加数据时,客户端可自行为新数据设置Entry ID,也可以让Redis服务器为其自动生成。Entry ID由两个部分组成: <millisecondsTime>-<sequenceNumber>;第一个部分是一个时间戳,表示新数据加入Stream的时间;第二个部分是序号,当两个或者多个数据在同一时刻生成时,可以使用序号区别它们。因此,从这两个部分的意义可以看出Entry ID是单调递增的。值得注意的是,当客户端指定Entry ID时,可使用自定义的Entry ID,只需确保Entry ID单调递增即可。例如,客户端可指定第一个元素的Entry ID为0-0,第二个元素的Entry ID为1-0。
Redis还为每一个消费者和消费者组保存一份状态信息。这些信息相互独立,一个消费者状态的变化不会改变其他消费者的状态。在这些信息中,Redis会记录当前消费者最后接收和处理的数据的Entry ID,以便于依次、逐个的向该消费者发送新接收的数据。
Redis也会为消费者组保存一份这样的信息,只是更为复杂的是,在一个消费者组中,Redis还会记录哪些消费者正在处理哪些数据。因为,当一位消费者接收到一份数据后,这份数据不会再次发给同组的其他消费者。与此同时,消费者也能向Redis查询自己正在处理的消息(这是为了能够让从错误状态中恢复的消费者完成正在处理的任务)。
图一 Streams的内部结构。
3 Streams的基本用法
3.1 向Streams添加数据
向Streams添加数据是由命令XADD完成的。例如,下面的命令创建了一个新的Stream,名字为littlewaterdrop_stream。该命令该向新的Streams添加了一个新的元素,该元素包含两个Key/Value对(name/Adam和age/18)。XADD命令中在第二个参数位置使用了星号*的意思是让Redis为新的数据自动生成一个Entry ID。当然,开发人员也可以自行给定一个Entry ID。唯一的限制是新的Entry ID必须大于已使用的任何一个Entry ID。因为在Redis内部,一个Stream的Entry ID是单调递增的。所以,在下面的第二个命令中,我们命令给出了Entry ID以添加第一个元素。最后,我们使用命令XLEN查询littlewaterdrop_stream中存放的元素的个数。目前是两个。
> XADD littlewaterdrop_stream * name Adam age 18
"1591478682515-0"
> XADD littlewaterdrop_stream 1591478682600-0 name Amy age 19
"1591478682600-0"
> XLEN littlewaterdrop_stream
(integer) 2
3.2 向Streams查询数据
XRANGE命令可以向Streams中查询Entry ID在某一范围内的数据。例如: 下面的命令查询littlewaterdrop_stream中所有的数据。其中减号-和加号+分别表示该Streams中的最小和最大Entry ID。
> XRANGE littlewaterdrop_stream - +
1) 1) "1591478682515-0"
2) 1) "name"
2) "Adam"
3) "age"
4) "18"
2) 1) "1591478682600-0"
2) 1) "name"
2) "Amy"
3) "age"
4) "19"
开发人员也可以根据具体的Entry ID的值来查询数据。例如:下面的命令查询Entry ID在1591478682515和1591478682600之间的数据。参数COUNT 2是可选参数,表示最多给出2个元素。如果不限制查询个数的话,该命令会查询在此范围内的所有数据。
> XRANGE littlewaterdrop_stream 1591478682515 1591478682600 COUNT 2
1) 1) "1591478682515-0"
2) 1) "name"
2) "Adam"
3) "age"
4) "18"
2) 1) "1591478682600-0"
2) 1) "name"
2) "Amy"
3) "age"
4) "19"
与XRANGE命令使用方法类似,XREVRANGE命令查询某一范围内的数据,并将其已逆序的顺序返回。注意,XRANGE接收的范围参数是start, end; 而XREVRANGE接收的范围参数是end, start;
> XREVRANGE littlewaterdrop_stream 1591478682600 1591478682515
1) 1) "1591478682600-0"
2) 1) "name"
2) "Amy"
3) "age"
4) "19"
2) 1) "1591478682515-0"
2) 1) "name"
2) "Adam"
3) "age"
4) "18"
3.3 从Streams读取数据
XREAD命令用于从Streams中读取数据。XREAD命令可用于多种场景之下,所以,我们将从最简单的场景开始,逐步深入。例如,如下的XREAD命令从littlewaterdrop_stream中读取Entry ID大于0的所有数据。该命令是非阻塞模式的XREAD命令,所有,该命令会返回当前littlewaterdrop_stream中的满足条件的所有数据。
> XREAD STREAMS littlewaterdrop_stream 0
1) 1) "littlewaterdrop_stream"
2) 1) 1) "1591478682515-0"
2) 1) "name"
2) "Adam"
3) "age"
4) "18"
2) 1) "1591478682600-0"
2) 1) "name"
2) "Amy"
3) "age"
4) "19"
XREAD命令可接收COUNT参数,表明最多可返回的数据个数。例如,下面的XREAD命令从littlewaterdrop_stream中读取Entry ID大于0的2个数据。
> XREAD COUNT 2 STREAMS littlewaterdrop_stream 0
1) 1) "littlewaterdrop_stream"
2) 1) 1) "1591478682515-0"
2) 1) "name"
2) "Adam"
3) "age"
4) "18"
2) 1) "1591478682600-0"
2) 1) "name"
2) "Amy"
3) "age"
4) "19"
除了非阻塞模式,XREAD命令还支持阻塞模式。开启阻塞模式只需要使用参数BLOCK即可。BLOCK参数之后紧随一个参数,表示最长阻塞的时间,单位为毫秒(MilliSecond)。在使用了BLOCK参数之后,XREAD命令会被阻塞直到要么超时、要么有新数据从Streams中读出。如果在执行XREAD时Streams已有可返回的数据的话,该XREAD命令直接返回,就像是执行非阻塞XREAD命令一样。如下的命令从littlewaterdrop_stream读取新数据。如果当前无新数据,该命令会最长等待100毫秒。这条命令使用了一个特殊的Entry ID。美元符号($)表示当前Streams中所使用最大的Entry ID。因此,该命令仅仅查询littlewaterdrop_stream中的新数据。
> XREAD BLOCK 100 STREAMS littlewaterdrop_stream $
XREAD命令还可以同时从多个Streams中读取数据。例如,下面的命令同时从littlewaterdrop_stream_1和littlewaterdrop_stream_2中读取新数据,最多等待100毫秒。
> XREAD BLOCK 100 STREAMS littlewaterdrop_stream_1 littlewaterdrop_stream_2 $ $
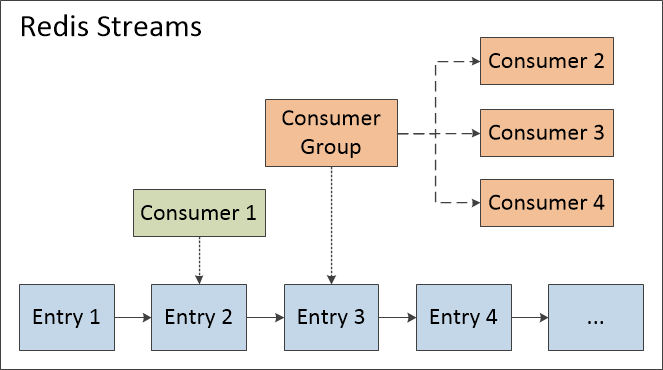
4 消费者组(Consumer Group)
使用XREAD命令已能够实现"多播"功能和"订阅-发布"功能。当有一个新的内容添加入Streams之后,每一个客户端都能收到一份新数据的拷贝。然而,在某些情况下,由于新数据的规模很多,我们希望使用一组客户端来协同处理这些新数据,将数据分配到各个客户端上处理。
Redis为了实现这个场景,设计了一个新的概念消费者组(Consumer Group)。当一个消费者组创建之后,它能够接收Streams上的所有数据,并将其数据分发给该组内的消费者(Consumer)。使用消费者组能确保:
- 每一条消息都能发给一个消费者,但是同一条消息不会发给两个或以上的消费者。
- 在组中,每个消费者由名字唯一标识。消费者组会保存每位消费者的状态,即使消费者发生断链错误,它也能在错误恢复后,重新连上消费者组,继续工作。
- 每处理一条消息,消费者需要向消费者组发送处理完毕的确认消息,用以将该消息从消费组中删除。
- 消费者组还会跟踪哪条消息由哪个消费者处理。因此,当消费者查询消息时,该消费者只能看到由自己处理的消息。
4.1 创建消费者组
XGROUP命令用于创建消费者组,并将其关联于Streams上。在下面的例子中,该命令在littlewaterdrop_stream上创建了一个消费者组littlewaterdrop_group。最后一个参数美元符号$表示littlewaterdrop_stream中使用的最大的Entry ID。开发人员也可以使用具体的Entry ID。其使用方法与XREAD命令类似。
> XGROUP CREATE littlewaterdrop_stream littlewaterdrop_group $
OK
如果Streams不存在的话,开发人员还可以使用参数MKSTREAM,让Redis自动创建一个Stream。例如:如果littlewaterdrop_stream不存在的话,下面的命令会自动创建一个Stream,命名为littlewaterdrop_stream。
> XGROUP CREATE littlewaterdrop_stream littlewaterdrop_group $ MKSTREAM
OK
4.2 从Streams读取数据
XREADGROUP命令用于从消费者组中读取数据。XREADGROUP的参数以及其意义与XREAD非常类似。它们都由BLOCK参数开启阻塞式读取模式。它们都使用COUNT来指定最大读取元素的个数。但是,不同的是,XREADGROUP命令接收GROUP参数,指明从哪个消费者组读取数据。GROUP参数之后紧接着的是消费者组的名称和消费者的名称。在消费者组中,消费者由其名称唯一确定。STREAMS参数之后紧接着的是Stream的名称以及Entry ID。下面的例子中使用了一个特殊的Entry ID:大于号(>)。它表示的意思是,此命令读取一条从未被其他消费者处理过的消息。所以,如果有多个消费者从一个消费者组中读取数据的话,它们将会获得不同的数据。
> XREADGROUP GROUP littlewaterdrop_group consumer1 COUNT 1 STREAMS littlewaterdrop_stream >
开发人员也可以指定一个具体的Entry ID,如下所示。
> XREADGROUP GROUP littlewaterdrop_group consumer1 COUNT 1 STREAMS littlewaterdrop_stream 1591478682515
4.3 确认消息已处理
当接收到一条消息之后,该消息会被标识为PENDING状态。当该消息被成功处理之后,消费者需要使用XACK命令通知Redis服务器该命令已处理完毕,将该消息标识为已处理。
> XACK littlewaterdrop_stream littlewaterdrop_group 1591478682515-0
5 小结
本章介绍了Redis的Streams的基本概念和用法。Streams的消费者组的概念是从kafka系统"借用"而来,但是Redis的实现方式完全不同。在Redis中,Streams数据结构能方便的支持"多播"方式的数据传播,将一条消息分发给多个接收端。在此基础之上,Redis设计了一个伪接收者:消费者组。消费者组接收所有的消息,但是,在一个消费者组中,消息是发送给不同的接收者处理的。在消费者组内的消息分发机制完全由开发人员(客户端)决定。
上一章
下一章
注册用户登陆后可留言