- 一、Redis系统介绍
- 二、Redis核心概念与体系结构
- 三、Redis数据类型
- 四、Redis事务处理(Redis Transactions)
- 五、发布-订阅系统(Publish/Subscribe System)
- 六、Streams
- 七、Redis序列化协议(REdis Serialization Protocol)
- 八、Redis单节点体系结构(Single Node Architecture)
- 九、数据持久化 (Data Persistence)
- 十、数据复制(Data Replication)
- 十一、高可用性(High Availability)和哨兵(Sentinel)机制
- 十二、Redis集群(Redis Cluster)
- 十三、Redis编程-Java篇
- 十四、Redis编程-Python篇
- 十五、小测验
第十章 数据复制(Data Replication)
1 概述
因为Redis将所有的数据存放在内存中,一旦系统重新启动或掉电,系统会丢失所有未写入硬盘的数据。为了提高数据的安全性,Redis支持数据复制功能(Data Replication)。数据复制功能是指当主数据库(Master Database)存储和处理数据的同时,Redis还支持从数据库(Slave Database)。主数据库会将新的数据变化同步到从数据库中。当主数据库发生错误,无法继续提供服务时,从数据库能代替主数据库继续提供服务。在Redis系统中,主数据库被称为Master,而从数据库被称为Slave或者Replica。一个主数据库能连接多个从数据库。从数据库还支持级联,即一个从数据库连接另一个从数据库。主数据库中的数据变化会沿着从数据库的连接链传递下去。
主从数据库之间的数据同步分为两种。第一种同步方式为全同步(Full Synchronization),即主数据库将当前所有的数据一次性全部发送给从服务器。第二种同步方式为增量同步(Incremental Synchronization),即主数据库会计算从数据库缺少的数据,并仅将缺少的那部分数据发给从数据库。在Redis文档中,又将增量同步称为部分同步(Partial Synchronization)。我们将在本章中详细介绍这两种同步方式。
当主数据发生错误时,Redis系统会选择一个从数据库,将其"晋升"为主数据库。这个属于哨兵(Sentinel)的功能,我们将在下一章介绍。
2 数据库的识别与数据比较
在介绍数据同步之前,我们需要理解Redis是如何识别和跟踪数据库的。在Redis系统中,Redis使用复制号(Replication ID)来唯一标识一个数据库。随着时间的推移,一个数据库可能会新增和删除一些数据。在这个变化的过程中,数据库的复制号是不变的。因此,主从数据库之间可以通过使用这个复制号来确定它们是否维护的是同一个数据库。
理论上,每当主数据库发生数据变更时,会向从数据库发送一份数据变更的消息。由此,主从数据库能够保持实时同步。然而,如果发生网络断连问题,主从数据库可能会在一段时间内无法同步数据。那么,从数据库就会发生数据同步滞后的问题。当从数据库再次与主数据库建立连接之后,主数据库如何得知从数据库缺少哪些信息呢?
解决这个问题的方法有很多,例如:记录每次数据同步的时间等。Redis采用了类似的方法:Redis使用偏移量(offset)的概念来跟踪数据的变化。其实,偏移量和时间戳的使用原理非常类似。主数据库自启动后,内部会初始化一个偏移量。每当数据发生变化时,主数据库会增加这个偏移量。偏移量是以字节为单位计算的。假如,当主数据库发生变化,需要向从数据库发送10个字节的数据以同步变化时,主数据库会将偏移量增加10,并将需要同步的数据放在缓冲区中。当增量同步发生时,主数据库可以使用这个偏移量从缓冲区中快速找出需要同步的数据。
在与从数据库数据同步时,主数据库会将这个偏移量与数据一起发给从数据库。当从数据库向主数据库发起数据同步请求时,从数据库也会将当前持有的偏移量包含在请求中。因此,主数据库可以通过从数据库当前持有的偏移量来判断从数据库的状态以及需要的数据。因此,一个二元组<Replication ID, OFFSET>能唯一确定在某一时刻数据库内的数据内容。
Redis的复制号是一个随机生成的字符串;而偏移量是一个整数。图一展示了一个主数据库跟踪数据状态变化的例子。在图中,x轴表示的是时间,假设Redis主数据库的复制号为e7d71fb600183a (真实的Redis系统中复制号更长)。在时刻A,假设当前偏移量的值是0x1234。在时刻A与时刻B之间,主数据库接收到了三条命令,分别新增三个Key/Value对(KEY1/VALUE1,KEY2/VALUE2,KEY3/VALUE3)。所以,到时刻B时,主数据库中的偏移量变为了0x5678。
假设在时刻A时,主从数据库发生断连错误,从数据库无法同步数据。该错误在时刻B恢复。因此,在时刻B,从数据库会向主数据库发起数据同步,并说明从数据库持有的偏移量是0x1234。那么,当主数据库收到同步请求后,主数据库通过比较偏移量能够计算出从数据库缺少新数据KEY1/VALUE1,KEY2/VALUE2,和KEY3/VALUE3。
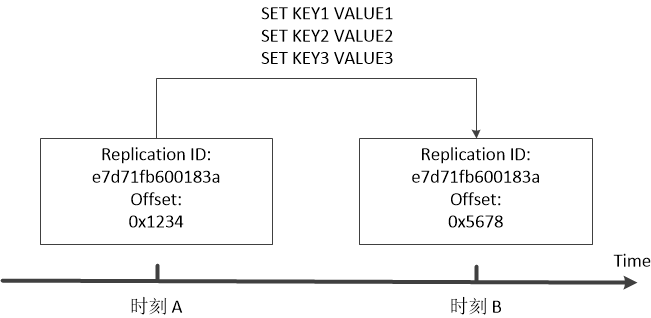
图一 Redis数据库状态跟踪。
从上面的例子我们会发现,保持偏移量以及相应的数据库的状态是需要消耗系统资源的。Redis不会保存所有的历史状态,而仅保留一部分。因此,当主数据库无法计算从数据库需要同步的数据时,从数据库只能发起全同步。我们将全同步和增量同步发生的场景总结如下。
全同步发生在:(1) 从数据库没有任何数据时。例如:新的从数据库请求数据同步;或者从数据库丢失了所有数据因而请求数据同步时;(2) 当主数据库无法计算增量同步所需的数据时。例如:从数据库的状态太老,主数据库已不再保留该数据状态。
增量同步发生在:当从数据保存了一些老数据,需要从主数据库中同步新增数据时,并且主数据库能够处理增量同步请求。
值得注意的是,如果当从数据库持有的复制号与主数据库不同时,会发生复制号不匹配错误而导致同步失败。
在理解了全同步和新增同步的应用场景后,我们在接下来的两个小节中分别介绍全同步和增量同步的处理过程。
3 全同步过程
下图是一个Redis数据全同步的时序图。数据同步是由主数据库和从数据库双方参与的过程。我们按照其步骤顺序解释双方的处理步骤。
- 当从数据库启动后,从数据库会主动与主数据库建立连接,并告知从数据库的IP地址、监听端口、和容量(Capacity)。因为,在启动时,从数据库知道主数据库的地址和端口,而主数据库并不知道从数据库的地址和端口。当连接建立之后,主从数据库之间就能双向通信了。主从服务器之间会发送PING和PONG命令检测连接状态。在从数据库端,主动建立连接的源代码在replication.c文件的connectWithMaster()函数中。
- 当连接建立之后,从数据库会向主数据库发送数据同步命令。新版本的Redis支持PSYNC命令(2.8.0及以上版本),同时也兼容SYNC命令。在从数据库端,从数据库是使用REPLCONF命令向主数据库发送IP地址、监听端口、和容量(Capacity)的。这段源代码在replication.c文件的syncWithMaster()函数中。在主服务器端,这些命令都是由对应的命令处理函数处理的。命令处理函数的数组声明在server.c文件中,处理PSYNC和SYNC命令的处理函数是replication.c文件中的syncCommand()函数。
- 当主数据库收到PSYNC命令或者SYNC命令后,主数据库会判断是否能进行增量数据同步。如果不行的话,主数据库会发起全同步。判断是否能使用增量同步的源代码在replication.c文件中的masterTryPartialResynchronization()函数中。
- 当主数据库决定使用全同步时,主数据库会首先向从数据库返回"+FULLRESYNC replication-id offset"字符串。在这个字符串中包含数据库的复制号和初始偏移量。这个发送响应消息的源代码在replication.c文件的replicationSetupSlaveForFullResync()函数中。
- 与此同时,主数据库开始生成RDB镜像文件。生成RDB镜像文件的源代码是在replication.c文件startBgsaveForReplication()函数中进行的。它调用了rdb.c文件中的rdbSaveBackground()函数进行后台生成。当Redis工作在无盘环境(Diskless Environment)中时,主服务器则调用rdbSaveToSlavesSockets()函数直接将数据写入与从服务器建立的连接流中。
- 主服务器会在serverCron()函数中检查RDB文件是否生成完毕。当RDB文件生成时,主服务器会调用sendBulkToSlave()函数将该文件发送给从服务器。从服务器在readSyncBulkPayload()函数中接收这个文件。
- 当接收完毕后,通过rdbLoad()函数将其加载入内容中,完成数据全同步。
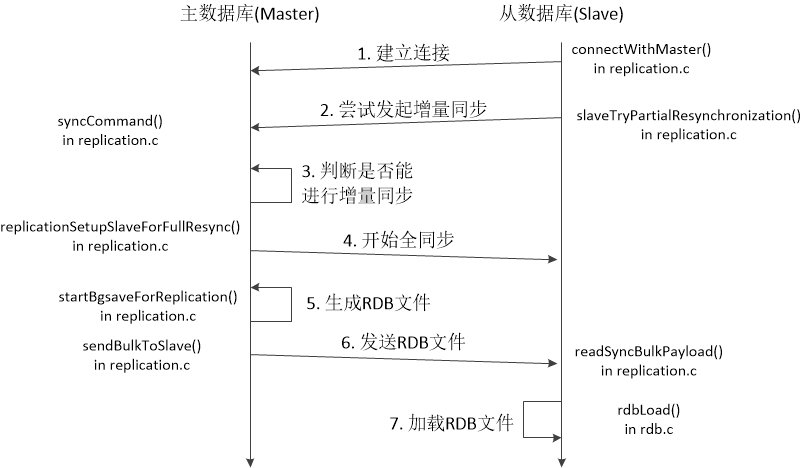
图二 Redis数据全同步时序图。
4 增量同步过程
在增量同步的过程中,前三个步骤与全同步相同。增量同步也是由从数据库发起的,并由主数据库来判断是否可行。所以,我们下面省略了前三个步骤,从第四步开始。
- 当主数据库认为增量同步可行时,主数据库会返回“CONTINUE”字符串。第三步和第四步的逻辑是在replication.c文件masterTryPartialResynchronization()函数中。
- 主数据库根据从数据库请求的偏移量计算从数据库缺失的数据,并将其发送给从数据库。缺失数据的计算和发送是在replication.c文件的addReplyReplicationBacklog()函数中实现的。如下面的代码所示,其实,数据库的偏移量是以字节计算的。所以,主数据库能够根据偏移量来计算从数据库缺少的数据的字节个数,并将其从server.repl_backlog中拷贝出来,组成一个新的简单字符串,发送给从数据库。server.repl_backlog中保存的是数据库变化的数据。最后,函数addReplySds将缺少的数据发送给从数据库。
// Redis 5.0.8 版本
// replication.c
long long addReplyReplicationBacklog(client *c, long long offset) {
...
/* Compute the amount of bytes we need to discard. */
skip = offset - server.repl_backlog_off;
/* Point j to the oldest byte, that is actually our
* server.repl_backlog_off byte. */
j = (server.repl_backlog_idx +
(server.repl_backlog_size-server.repl_backlog_histlen)) %
server.repl_backlog_size;
/* Discard the amount of data to seek to the specified 'offset'. */
j = (j + skip) % server.repl_backlog_size;
/* Feed slave with data. Since it is a circular buffer we have to
* split the reply in two parts if we are cross-boundary. */
len = server.repl_backlog_histlen - skip;
while(len) {
long long thislen =
((server.repl_backlog_size - j) < len) ?
(server.repl_backlog_size - j) : len;
addReplySds(c,sdsnewlen(server.repl_backlog + j, thislen));
}
return server.repl_backlog_histlen - skip;
}
- 最后,从数据库依次读取并执行同步过来的数据。在replicationResurrectCachedMaster()函数中,从数据库设置了Event Loop的处理函数,当可以从连接newfd读取数据时,Event Loop会回调readQueryFromClient()函数处理数据。
// Redis 5.0.8 版本
// replication.c
void replicationResurrectCachedMaster(int newfd) {
...
linkClient(server.master);
if (aeCreateFileEvent(server.el, newfd, AE_READABLE, readQueryFromClient, server.master)) {
...
}
...
}
增量同步的处理时序图如下所示。
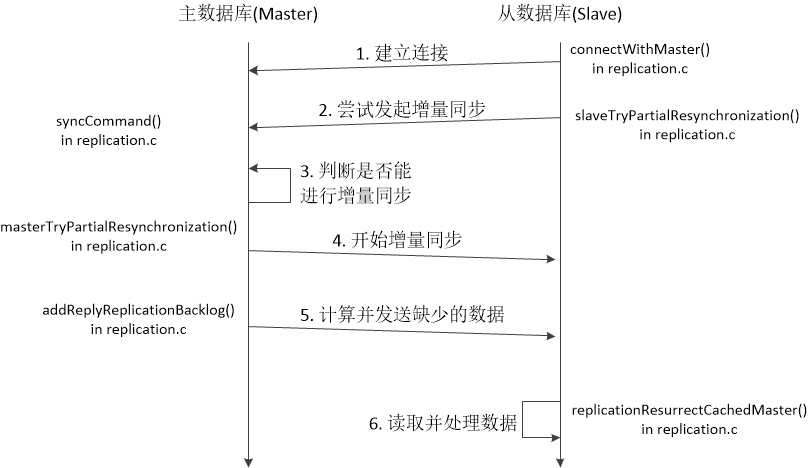
图三 Redis数据增量同步时序图。
5 小结
本章介绍了Redis的两种同步过程。在理解同步原理之前,我们先介绍了Redis如何确定和判断数据的状态。Redis使用复制id来唯一确定一个数据库;使用偏移量来确定数据库的状态。每当主数据库的数据发送变化时,主数据库会增加其偏移量。我们将在下一章讲解哨兵(Sentinel)功能。Redis通过哨兵功能检查主从数据库的状态。如果主数据库无法正常工作的话,Redis会选择一个从数据库晋升为主数据库继续提供服务。
上一章
下一章
注册用户登陆后可留言