- 一、Redis系统介绍
- 二、Redis核心概念与体系结构
- 三、Redis数据类型
- 四、Redis事务处理(Redis Transactions)
- 五、发布-订阅系统(Publish/Subscribe System)
- 六、Streams
- 七、Redis序列化协议(REdis Serialization Protocol)
- 八、Redis单节点体系结构(Single Node Architecture)
- 九、数据持久化 (Data Persistence)
- 十、数据复制(Data Replication)
- 十一、高可用性(High Availability)和哨兵(Sentinel)机制
- 十二、Redis集群(Redis Cluster)
- 十三、Redis编程-Java篇
- 十四、Redis编程-Python篇
- 十五、小测验
第九章 数据持久化 (Data Persistence)
1 概述
数据持久化(Data Persistence)的过程是将数据写到持久化的设备(例如:硬盘)上。当系统重新启动后,这些数据不会丢失,它们还能从持久化的设备中读取出来。正如我们在第二章介绍的那样,Redis支持两种数据持久化方式:RDB(Redis Database Backup)方式和AOF(Append Only File)方式。我们将会在本章中详细介绍这两种持久化方式的工作原理。另外,一般在讨论数据持久化问题的时候,会从两个方面考虑这个问题:其一是数据持久化的过程,即如何将数据写入持久化设备上;另一个方面是如何从持久化设备上恢复数据。我们会在本章中讲解这两个应用场景。
2 RDB方式的数据持久化
在RDB持久化方式下,Redis会通过创建数据库的镜像(Database Snapshot)来备份数据库。Redis支持两种方法创建数据库镜像。第一种是自动备份;在Redis配置文件中,开发人员可以配置创建镜像的条件。当这些条件满足时,Redis会自动的创建一个镜像。例如:当在900秒时间内,有一个Key发生了变化,则创建一个镜像。第二种是手动备份。当开发人员下达SAVE命令或者BGSAVE命令后,Redis会创建一个RDB镜像。SAVE命令与BGSAVE命令不同之处在于BGSAVE命令指在后台线程完成镜像创建,它不会阻塞其他命令的处理。这种创建方法又被称为异步处理(Asynchronous Processing)。
自动备份的处理方式。在Redis内部还维护着定时器功能。当Redis中数据发生变化时,Redis会保存这些变化的次数、频率等信息。Redis会每隔一段时间检查这些信息。当这些信息满足开发人员设置的条件时,Redis则会创建一个RDB数据备份(稍后讲解)。
SAVE命令的处理方式。当Redis收到SAVE命令后,立即创建一个RDB数据备份(稍后讲解)。
BGSAVE命令的处理方式。当Redis收到BGSAVE命令后,Redis仅仅设置一个标记,表示需要创建一个数据备份。Redis会每隔一段时间检查是否需要创建一个备份。如果该标记被置为true,则Redis会创建一个数据备份。
我们可以发现,完成上述三个功能的两个关键点是:Redis如何每隔一段时间检查是否需要备份,和备份的创建过程。我们将在下面的内容中详细讲解。
2.1 定时器功能
我们还记得在上一章讲解Event Loop时讲过,Event Loop是一个无限循环。在循环中,Redis每次会调用aeProcessEvents()函数来处理事件。当aeProcessEvents()函数处理完事件之后,它还会检查定时器是否超时。如果超时,则会调用相应的超时函数(Timeout Handler)。
// Redis 5.0.8 版本
// Event Loop的代码大部分在ae.h和ae.c中
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) { //不断的监听和处理事件
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
...
if (flags & AE_TIME_EVENTS) // 处理定时器
processed += processTimeEvents(eventLoop);
return processed;
}
static int processTimeEvents(aeEventLoop *eventLoop) {
...
if (now_sec > te->when_sec ||
(now_sec == te->when_sec && now_ms >= te->when_ms))
{
...
retval = te->timeProc(eventLoop, id, te->clientData); //调用超时函数
}
}
在Redis初始化时,Redis会创建一个定时器serverCron,每1毫秒超时一次。serverCron这个名字非常贴切,他就像Linux平台上的定时任务(cron job)那样每隔一段时间运行一次。
// Redis 5.0.8 版本
// server.c
void initServer(void) {
/* Create the timer callback, this is our way to process many background
* operations incrementally, like clients timeout, eviction of unaccessed
* expired keys and so forth. */
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create event loop timers.");
exit(1);
}
}
在serverCron()函数中,这里有两处代码需要留意。第一处代码是检查当前状态是否满足创建RDB的条件。如果满足,则调用rdbSaveBackground()函数创建镜像。第二处代码是检查是否设置了在后台创建RDB镜像。这个标志位是由BGSAVE命令设置的。如果设置了,则调用rdbSaveBackground()函数创建镜像。
// Redis 5.0.8 版本
// server.c
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
...
/* If there is not a background saving/rewrite in progress check if
* we have to save/rewrite now. */
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
/* Save if we reached the given amount of changes,
* the given amount of seconds, and if the latest bgsave was
* successful or if, in case of an error, at least
* CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
...
/* Start a scheduled BGSAVE if the corresponding flag is set. This is
* useful when we are forced to postpone a BGSAVE because an AOF
* rewrite is in progress.
*
* Note: this code must be after the replicationCron() call above so
* make sure when refactoring this file to keep this order. This is useful
* because we want to give priority to RDB savings for replication. */
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 &&
server.rdb_bgsave_scheduled &&
(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
if (rdbSaveBackground(server.rdb_filename,rsiptr) == C_OK)
server.rdb_bgsave_scheduled = 0;
}
}
因此,我们在简要的总结一下Redis定时功能的处理流程。在Redis服务器初始化时,Redis创建了一个定时器serverCron,它每毫秒执行一次。定时器的执行是由Event Loop触发的。在事件处理完后,Event Loop还会执行定时器处理函数。在定时器处理函数中,Redis会检查是否需要创建RDB数据镜像。如果需要,则创建一个RDB镜像。RDB镜像的处理过程将在2.3小节介绍。
2.2 SAVE命令和BGSAVE命令处理过程
在进入镜像创建过程之前,我们先简单介绍一下SAVE命令和BGSAVE命令的处理过程。如上一章介绍的那样,SAVE命令和BGSAVE命令的处理函数是定义在redisCommandTable数组里的。SAVE命令的处理函数是saveCommand,BGSAVE命令的处理函数是bgsaveCommand。
// Redis 5.0.8 版本
// server.c
struct redisCommand redisCommandTable[] = {
...
{"save",saveCommand,1,"as",0,NULL,0,0,0,0,0},
{"bgsave",bgsaveCommand,-1,"as",0,NULL,0,0,0,0,0},
...
}
SAVE命令的处理较为简单,就是调用rdbSave()函数创建一个RDB镜像。只有在镜像文件创建成功之后,该函数才会返回。因此,这种创建方法被称为同步创建(Synchronous Processing)。它会阻塞Redis数据库处理其他的命令。BGSAVE命令的处理也很简单,就是将server.rdb_bgsave_scheduled设置为1。然后,Redis会在上述的定时处理函数serverCron()中创建一个RDB镜像。
// Redis 5.0.8 版本
// rdb.c
void saveCommand(client *c) {
...
if (rdbSave(server.rdb_filename,rsiptr) == C_OK) {
addReply(c,shared.ok);
}
...
}
void bgsaveCommand(client *c) {
...
if (schedule) {
server.rdb_bgsave_scheduled = 1; // 设置标识位
addReplyStatus(c,"Background saving scheduled");
}
...
}
2.3 RDB镜像的创建过程
在上面介绍的流程中,Redis可能会调用rdbSaveBackground()函数或者rdbSave()函数创建RDB镜像。rdbSaveBackground()函数名称的意思是在后台创建一个RDB镜像。它的实现很简单,就是通过使用fork()系统调用,创建一个子进程。然后,在子进程中调用rdbSave()创建一个RDB镜像。在fork()系统调用完成后,Redis服务器成为了父进程,而新的子进程则会创建RDB镜像。fork()系统调用还能保证在系统调用完毕之后,子进程能继承父进程中的所有数据(有一些列外:例如进程ID会不同),因此,子进程也能获取Redis数据库中的所有数据,并将其写入文件。
// Redis 5.0.8 版本
// rdb.c
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
...
if ((childpid = fork()) == 0) {
/* Child */
...
retval = rdbSave(filename,rsi); // 在子进程中调用rdbSave()函数创建RDB镜像
...
} else {
/* Parent */
...
}
return C_OK;
}
那么,RDB镜像创建过程中最为核心的内容就是在rdbSave()函数里了,或者更具体的说是在rdbSaveRio()函数里。RDB是一个二进制文件(Binary File)。因此,所有写入RDB文件中的数据必须转换为二进制,然而再写入文件。这个过程也被常常称为序列化(Data Serialization或者Data Marshalling)。
rdbSaveRio()函数大致的执行顺序如下:
- 首先写入的是魔数(Magic Number)。魔数是一个固定的数,用于检查这个文件是不是RDB文件。目前,Redis使用的魔数是"REDIS"字符串。
- 遍历所有的DB。在单节点模式下,Redis服务器只有一个DB。
- 对于每一个DB,首先写入DB开始的标识符(单字节0xFE)。
- 紧接着是DB号和DB的大小。
- 然后遍历DB中每对Key/Value的值,并将其写入文件。
- 最后是写入DB结束标识(单字节0xFF),和校验和(checksum)。
// Redis 5.0.8 版本
// rdb.c
int rdbSave(char *filename, rdbSaveInfo *rsi) {
...
if (rdbSaveRio(&rdb,&error,RDB_SAVE_NONE,rsi) == C_ERR) {
errno = error;
goto werr;
}
...
}
int rdbSaveRio(rio *rdb, int *error, int flags, rdbSaveInfo *rsi) {
...
// 写入魔数,魔数的长度为9
if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
...
// 遍历所有的db。在单节点模式下,Redis只有一个db
for (j = 0; j < server.dbnum; j++) {
redisDb *db = server.db+j;
dict *d = db->dict;
if (dictSize(d) == 0) continue;
di = dictGetSafeIterator(d);
// 写入db开始的标识 0xFE
if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;
// 写入db号
if (rdbSaveLen(rdb,j) == -1) goto werr;
// 写入 db大小
if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;
if (rdbSaveLen(rdb,db_size) == -1) goto werr;
if (rdbSaveLen(rdb,expires_size) == -1) goto werr;
// 遍历db中每个Key/Value对
while((de = dictNext(di)) != NULL) {
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
...
if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;
...
}
}
// 写入DB结束的标识符 0xFF
if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
// 最后写入校验和(checksum)
cksum = rdb->cksum;
memrev64ifbe(&cksum);
if (rioWrite(rdb,&cksum,8) == 0) goto werr;
return C_OK;
}
因此,我们将RDB文件的格式总结在下图中。
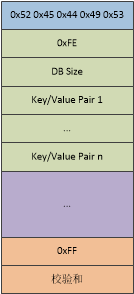
图一 RDB文件格式(RDB Layout)。
2.4 从RDB镜像文件中恢复数据
从RDB镜像文件中恢复数据的过程其实是镜像文件创建的逆向过程。Redis按照RDB文件的格式依次读取数据。Redis服务器数据恢复的过程也比较简单。当Redis服务器启动时,main()函数会调用loadDataFromDisk()函数。在loadDataFromDisk()函数中,Redis会判断是从RDB文件中恢复数据,还是从AOF文件中恢复数据。
// Redis 5.0.8 版本
// server.c
int main(int argc, char **argv) {
...
loadDataFromDisk();
...
}
void loadDataFromDisk(void) {
long long start = ustime();
if (server.aof_state == AOF_ON) {
// 从AOF文件中恢复数据
if (loadAppendOnlyFile(server.aof_filename) == C_OK)
serverLog(LL_NOTICE,"DB loaded from append only file: %.3f seconds",(float)(ustime()-start)/1000000);
} else {
// 从RDB文件中恢复数据
rdbSaveInfo rsi = RDB_SAVE_INFO_INIT;
if (rdbLoad(server.rdb_filename,&rsi) == C_OK) {
...
}
}
}
如果是从RDB文件中恢复数据,则调用rdbLoad()函数。而真正的加载过程是在rdbLoadRio()函数中进行的。它的过程就是rdbSaveRio()函数的逆向过程。首先匹配魔数"REDIS",然后依次读取DB中所有的Key/Value对。我们在这里略去了这个函数的实现细节。有兴趣的读者可在rdb.c文件中搜索rdbLoadRio()函数。
3 AOF方式的数据持久化
AOF持久化的原理是Redis服务器记录下所有的操作,并将其记录在AOF文件的尾部。当需要从AOF文件中恢复数据时,Redis服务器只需依次从AOF文件中读出每一项记录,再重新执行这些记录即可。
3.1 AOF处理过程
我们在第二章介绍过,当Redis执行一条客户端发来的命令时,在call()函数中调用了各个命令的处理函数。当AOF功能开启时,call()函数还会调用propagate()函数,将命令写入AOF的buffer中。
// Redis 5.0.8 版本
// server.c
void call(client *c, int flags) {
...
c->cmd->proc(c); // 执行命令
...
if (propagate_flags != PROPAGATE_NONE && !(c->cmd->flags & CMD_MODULE))
// 将该命令再次发送给自己
propagate(c->cmd,c->db->id,c->argv,c->argc,propagate_flags);
...
}
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags)
{
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
feedAppendOnlyFile(cmd,dbid,argv,argc);
}
Redis是将命令依次写入AOF文件的,但是,这并不代表着AOF中存放的是相同的命令。因为,AOF文件只需要保证依次读取其中的数据就能恢复数据库的内容。所以,在一些场景下,Redis会修改命令的内容。例如:INCRBYFLOAT命令会被转换为SET命令,因为Redis只需要记住最后的计算结果就可以恢复数据。具体的转换规则可参见feedAppendOnlyFile()函数。
命令的内容被转换为简单字符串(SDS),写入了server.aof_buf中。在Event Loop进入下一次循环之前,Redis会将aof_buf的内容写入持久化设备(如果查看Event Loop的无限循环,在处理命令之前,Event Loop会调用beforesleep函数。这个beforesleep函数就是server.c文件中的beforeSleep()函数,它会将aoe_buf的内容写入持久化设备)。
// Redis 5.0.8 版本
// aof.c
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
sds buf = sdsempty();
...
if (server.aof_state == AOF_ON)
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
if (server.aof_child_pid != -1)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
}
// server.c
void beforeSleep(struct aeEventLoop *eventLoop) {
flushAppendOnlyFile(0);
}
3.2 AOF重写(AOF Rewrite)
我们在介绍feedAppendOnlyFile()函数时,并没有介绍最后一个函数调用(aofRewriteBufferAppend),因为这是用于AOF重写的。当Redis正在进行AOF重写时,也需要向AOF重写任务发送一份正在执行的命令。AOF持久化方法的一个致命问题是AOF文件会慢慢增大。Redis采用了AOF重写机制,以防止AOF文件无限增长下去。
Redis会监控AOF文件的长度,当长度超过设置的阈值时,Redis会启动AOF重写,即根据目前的数据重新生成一个AOF文件以取代旧的文件。AOF重写并不依赖于正在使用的AOF文件;换句话说,AOF重写并不会从头开始读取当前AOF文件中的记录。AOF重写会直接从Redis数据库中读取数据,这样可以节省不必要的读操作。AOF重写是异步执行的。在Redis处理AOF重写的同时,Redis还可以接收和处理客户端发来的命令。因此,在AOF重写的进行过程中,如果数据发生了变化,Redis也需要向AOF重写的过程发送一份命令,已确保新生成的AOF文件包含最新的数据。上述的AOF重写过程是自动触发方式,开发人员还可以使用BGREWRITEAOF命令手动触发AOF重写。
AOF重写的检测也是在serverCron()函数中进行的。该函数每毫秒执行一次。在下面的代码中,第一处代码检查开发人员是否执行了BGREWRITEAOF命令。如果已经执行了该命令,server.aof_rewrite_scheduled会被设置为true。BGREWRITEAOF命令的执行过程可参考aof.c文件中的bgrewriteaofCommand()函数。在下面的第二处代码中,Redis检查当前AOF文件的大小,如果超过设置的阈值的话,则执行rewriteAppendOnlyFileBackground()函数。
// Redis 5.0.8 版本
// server.c
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
...
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
...
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
...
}
与之前分析的RDB镜像(rdbSaveBackground函数)生成的过程类似,rewriteAppendOnlyFileBackground()函数也会使用fork()系统调用创建一个子进程。因为此时,子进程(新创建的进程)会包含父进程(Redis服务器)所有的数据,因此,rewriteAppendOnlyFile()函数能将所有的数据写入AOF文件中。
真正的将数据写入AOF文件是在rewriteAppendOnlyFileRio()函数中进行的。与RDB文件创建的过程类似,Redis也会遍历每个Key/Value对,并根据不同的数据类型,将其写入AOF文件中。相关的细节内容可参考aof.c文件中的rewriteAppendOnlyFileRio()函数。
int rewriteAppendOnlyFileBackground(void) {
...
if ((childpid = fork()) == 0) {
...
/* Child */
if (rewriteAppendOnlyFile(tmpfile) == C_OK) {
...
}
} else {
...
/* Parent */
}
...
}
4 小结
本章详细介绍了Redis支持的RDB和AOF两个持久化方法,并辅以源代码讲解其处理过程。RDB和AOF的原理各有利弊,RDB能完整的记录下某个时间点的数据库内容,且数据恢复的速度快。在RDB镜像创建完毕之后,RDB方法则不能记录新增的数据。而AOF会记录下所有的数据内容;当系统发送错误时,能最大的减少数据丢失。
上一章
下一章
注册用户登陆后可留言