- 一、Redis系统介绍
- 二、Redis核心概念与体系结构
- 三、Redis数据类型
- 四、Redis事务处理(Redis Transactions)
- 五、发布-订阅系统(Publish/Subscribe System)
- 六、Streams
- 七、Redis序列化协议(REdis Serialization Protocol)
- 八、Redis单节点体系结构(Single Node Architecture)
- 九、数据持久化 (Data Persistence)
- 十、数据复制(Data Replication)
- 十一、高可用性(High Availability)和哨兵(Sentinel)机制
- 十二、Redis集群(Redis Cluster)
- 十三、Redis编程-Java篇
- 十四、Redis编程-Python篇
- 十五、小测验
第一章 Redis系统介绍
1 概要
Redis是目前最为流行的一个Key-Value内存数据库(Key-Value In-Memory Database)。它不仅能用作数据库管理数据,而且还常常用于缓存(Caching)或者消息转发(Message Broker)等场景。Redis取自于它的全名REmote DIctionary Server。
Redis是一个小巧的数据库,它由C语言实现,总共约2万行代码。Redis支持多种数据类型,例如,字符串(String)、链表(List)、集合(Set)、哈希表(Hash Table)等。在Redis中,因为所有的数据都存放在内存中,所以,Redis还支持可选的数据持久化功能。当数据持久化功能开启时,数据库重启不会丢失数据。Redis可运行于单节点环境或者分布式集群环境;在分布式环境下,数据能在不同节点之间同步和备份。Redis具有小巧、性能好、扩展性好等优点,因此,它是目前最为流行的一种Key-Value数据库。至今,Redis已更新至5.0.8版本。读者可在Redis的官方网站上获得更多信息和源代码。
因为Redis是一种NoSQL数据库;它的工作方式和特点与传统的关系型数据库(Relational Database)不同。因此,本章首先从理论的角度比较关系型数据库与NoSQL数据库,分析其优缺点。然后,再解释并总结Redis数据库的特性,为正式进入Redis的内容打下理论基础。
2 关系型数据库(Relational Database) VS. NoSQL数据库(NoSQL Database)
2.1 关系型数据库(Relational Database)
关系型数据库是一种最为通用的数据库类型。它建立于关系模型(Relational Model)之上。具体地讲,它使用表(Table)或者视图(View)来表达数据之间的关系。在关系型数据库中,开发人员可以使用SQL (Structured Query Language) 编程语言来创建、删除、或者查询数据。
关系型数据库的应用场景非常广。在数据关系确定之后,开发人员能够根据数据之间的关系创建表和视图来存储和表达数据。然而,随着互联网的发展和数据大规模地快速增长,关系型数据库面临了诸多挑战。以下两个问题启发了人们开发新类型的数据库。
- 数据之间的关系变得更加多样化、复杂化,难以使用统一的规则来表达。因为在关系型数据库中,每一项数据都有着自身的类型,而且在表中,每一栏(Column)只能存放类型相同的数据。严格的数据类型校验为开发人员带来了方便的同时,也限制了其应用面。以构建网页数据库为例,该数据库的目的是为了存放网页的内容,包括文字,图片,音频和视频等各种信息。如果使用关系型数据库的话,数据之间的关系会变得非常复杂(例如:开发人员需要考虑各项数据之间的顺序)。因此,在此场景下,Key-Value数据库或者文档数据库可能是一个更好的选择。
- 数据快速增长(大数据),超过了传统关系型数据库的处理能力。为了提高查询和数据处理的能力,一种常用的方法是将数据切分为多个分区;将各个分区分散在多个服务器上处理。这种方法常被称为数据处理并行化(Data Processing Parallelization)。然而,由于关系型数据库支持多种数据操作;有些操作“限制”了关系型数据库的并行化。例如,在查询操作中,表连接(Join Operator)操作是最为耗时的一项操作。如果将一张表分散存储在多个服务器上,那么,表连接操作将变得更加复杂。在并行/分布式环境下,索引的创建和维护也是一项非常复杂的任务。
人们在关系型数据库并行化方向付出了诸多努力,然而,在许多场景下收获不多。因此,人们逐渐意识到,数据库不应该是一个大而全的系统。未来的数据库系统应该是精准定位于某一特定场景的系统。如果读者对数据库未来发展感兴趣的话,可以阅读下面这两篇文章。这两个文章的作者是2015年图灵奖获得者迈克尔·斯通布雷克(Michael Stonebraker)。他在文章中的观点是:单纯使用关系型数据库来管理现代数据的时代已结束。未来将会出现各种各样的数据库来处理某一特定场景。
- "One Size Fits All: An Idea Whose Time Has Come and Gone", M. Stonebraker and U. Cetintemel, 2005.
- "The End of an Architectural Era (It's Time for a Complete Rewrite)", M. Stonebraker, N. Hachem, and P. Helland, 2007.
2.2 NoSQL数据库(NoSQL Database)
NoSQL数据库是另一种数据库类型。起初,NoSQL的意思是"No SQL System",即不使用SQL语言的数据库。而如今,NoSQL数据库阵营逐渐发展壮大,NoSQL的意义也变为了"Not Only SQL"。
从本质上讲,NoSQL是指不使用关系型模型构建数据库。目前,NoSQL数据库可分为四类,它们是:Key-Value数据库(例如:Redis,AWS DynamoDB);文档数据库(Document-Oriented Database,例如:MongoDB,AWS DocumentDB);图数据库(Graph Database,例如:Neo4j,AWS Neptune);和Wide Column数据库(例如:Apache Cassandra)。当然,也有些数据库集多种数据模型于一身,例如ArangoDB支持Key-Value模型,文档模型,和图模型。在下面的内容中,我们着重讲解Key-Value数据库。
从理论上看,Key-Value数据库并不是一个新的概念。它与关联数组(Associative Array),哈希表(Hash Table),或者字典(Dictionary)的概念非常类似。Key-Value数据库管理着一组Key/Value对;Key和Value可以是任意结构的数据。除了添加和删除Key-Value数据以外,Key-Value数据库最核心的功能是提供快速使用Key对象来查询Value对象的查询功能。
 图一 Key-Value数据库。
图一 Key-Value数据库。
Key-Value数据库一般使用下述的两个步骤建立从Key到Value的映射。在实际应用中,这个映射逻辑常常体现在从Key到Value的查询过程或者索引的建立过程中。图二展示了从Key映射到Value的过程。
- 首先,第一步是Key归一化(Key Normalization)。因为Key-Value数据库支持多种不同类型的Key。如果在Key上建立索引的话,首先需要用一种通用的方法来表示Key。一种常见的方法是使用哈希函数(Hash Function),因为哈希函数能将任意类型的数据转化为固定类型、固定大小的值。但是,哈希函数并不是唯一的做法。例如,Redis使用了Key对象在内存中的二进制数据来做索引。因此,在Redis中,Key归一化的过程就是获取Key在内存中二进制数据内容的过程。
- 第二步就是在Key归一化之后建立索引。因为Key对象的类型已归一为同一种类型的数据了,所以,理论上,任意一种索引算法都能应用于Key-Value数据库中。
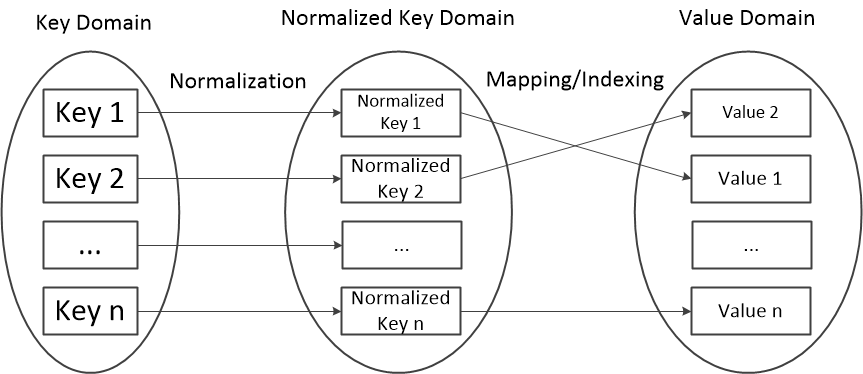 图二 从Key到Value的映射。
图二 从Key到Value的映射。
2.3 Key-Value数据库的缺点
Key-Value数据库的特点是从Key到Value的查询速度非常快;Key-Value数据库能容纳超大规模的数据。但是,Key-Value数据库的缺点也同样非常明显。我们将其缺点总结如下。
- 因为Key和Value可以是任意类型的数据。所以,应用程序需自行解析/处理Key/Value中的数据。数据库不能提供类型检查和校验,也无法提供统一的操作。
- Key-Value数据库无法支持高效的范围查询(Range Query)。在归一化后,Key对象之间的逻辑关系(例如:大小关系)已不复存在。因此,Key-Value数据库无法根据内部索引进行范围查询。然而,在关系型数据库中,范围查询是最为常用的查询类型之一。例如,如下SQL查询语句在表Product中查找所有价格高于80圆的商品。
SELECT name
FROM Product
WHERE price > 80.00
;
- Key-Value数据库无法支持高效的模式匹配查询(Pattern Matching Query)。与第二点相似,Key-Value数据库必须扫描所有的数据以完成下面的查询:在Product表中查找在商品描述字段中包含关键字"Book"的所有商品。
SELECT name
FROM Product
WHERE description like '%Book%'
;
- Key-Value数据库无法支持高效的基于属性的查询(Query based on Properties rather than Key),因为Key-Value数据库只对Key做了索引。例如,如下查询语句在表Product中查找商品描述字段的长度超过100个字的所有商品。
SELECT name
FROM Product
WHERE character_length(description) > 100
;
- Key-Value数据库不支持重复的Key;这一点与关系型数据库中Primary Key类似。
3 Redis数据库
在理解了Key-Value数据库之后,理解Redis就不那么困难了。我们将Redis的特性特点总结如下。
- Redis是一个内存数据库;它将所有数据存放在内存中,以最快的速度处理和响应请求。
- Redis是Key-Value数据库;它将数据分为Key和Value,并对Key建立索引。在这种存储方式下,从Key到Value的查询非常快,而且这种存储方式易于扩展。但是,这种方法不支持高效的范围查询(Range Query)、模式匹配查询(Pattern Matching Query)和基于属性的查询。
- Redis支持可选的持久化(Optional Persistence)。当持久化功能开启时,数据会保存在磁盘上。数据库重启不会丢失数据。Redis支持异步保存,即当Redis收到新的数据后,Redis能立刻应答请求,而无需等待数据存储完毕之后才应答。这种设计也是为了缩短数据请求响应的时间。
- Redis支持单机模式(Single Node Mode)和集群模式(Cluster Mode)。在单机模式下,所有的数据存放在本机中;在集群模式下,数据会被切分并分布在集群的各个节点上。
- Redis支持可选的数据备份(Data Replication)。当该功能开启时,数据自动的从主服务器(Master Server)备份到从服务器(Slave Server)。当主服务器故障时,Redis还具备自动故障恢复机制(Failure Recovery Mechanism)。
- Redis内置了Lua解释器。在Redis中能运行Lua程序。
4 总结
本章主要介绍Redis系统的基本内容。因为Redis是一个Key-Value数据库,它的工作方式与关系型数据库有许多不同之处。因此,本文还比较了这两种数据库的特点。Key-Value数据库(或者Redis)不能解决所有问题,但是,它能够很好的解决某一些具体问题。
我们将在接下来的章节中逐个介绍Redis各个部分的功能,后续章节安排如下。
- 第二章 Redis核心概念与体系结构(Concepts and Architecture of Redis)
- 第三章 Redis数据类型
- 第四章 Redis事务处理(Redis Transactions)
- 第五章 发布-订阅系统(Publish/Subscribe System)
- 第六章 Streams
- 第七章 Redis序列化协议(REdis Serialization Protocol)
- 第八章 Redis单节点体系结构(Single Node Architecture)
- 第九章 数据持久化 (Data Persistence)
- 第十章 数据复制(Data Replication)
- 第十一章 高可用性(High Availability)和哨兵(Sentinel)机制
- 第十二章 Redis集群(Redis Cluster)
- 第十三章 Redis编程-Java篇
- 第十四章 Redis编程-Python篇
下一章
注册用户登陆后可留言