- 一、Redis系统介绍
- 二、Redis核心概念与体系结构
- 三、Redis数据类型
- 四、Redis事务处理(Redis Transactions)
- 五、发布-订阅系统(Publish/Subscribe System)
- 六、Streams
- 七、Redis序列化协议(REdis Serialization Protocol)
- 八、Redis单节点体系结构(Single Node Architecture)
- 九、数据持久化 (Data Persistence)
- 十、数据复制(Data Replication)
- 十一、高可用性(High Availability)和哨兵(Sentinel)机制
- 十二、Redis集群(Redis Cluster)
- 十三、Redis编程-Java篇
- 十四、Redis编程-Python篇
- 十五、小测验
第三章 Redis数据类型
1 引言
作为一个数据库管理系统,Redis支持一些基本的数据类型。开发人员可以直接使用这些数据类型,建立应用程序。
Redis支持的数据类型有:字符串(String),链表(List),哈希表(Hash),集合(Set),有序集合(Sorted Set),位图(Bitmaps),HyperLogLogs,和流(Stream)。其中,集合(Set)常常被称为无序集合(Unordered Set);哈希表(Hash)常被称为映射表(Map)或者字典(Dictionary)。
我们将在本章逐一介绍上述内置的数据结构(流Streams将放在第六章介绍)。我们首先会介绍各个数据结构的含义以及基本操作。然后我们还会简略的讲解这些数据类型的内部实现。我们鼓励读者去阅读Redis的源代码,因为Redis的实现非常简单,代码清晰易读。为此我们会给出相对应的源代码文件名,读者可以根据兴趣选择阅读。
2 字符串类型(String)
2.1 字符串的基本操作
字符串是最为常见的一种数据类型。在Redis中,字符串可以作为Key或者Value使用。在实际应用中,人名(例如:“Bob”),商品名称(例如:“Book”),或者一个网页的内容(例如:HTML字符串)都可以用一个字符串来表达。
如果我们打开一个Redis的客户端,我们可以创建Key/Value的类型均为字符串的数据。例如:
> SET name "Little Waterdrop"
OK
> GET name
"Little Waterdrop"
> STRLEN name
(integer) 16
在上面的操作中,我们首先使用SET命令成功的创建了一个Key/Value的记录。Key是字符串"name",Value是字符串"Little Waterdrop"。因为Value字符串的值包含一个空格,所以将其放在双引号之中。第二行打印“OK”表示的是第一条指令执行的结果。在创建好第一条记录之后,我们使用了get命令获取了"name"对应的值,即为"Little Waterdrop"。我们还可以通过STRLEN指令计算字符串的长度。
到这里,我们完成了对于字符串的最基本操作。那么,读者可能会有一个问题,Redis支持整数吗?当然支持。但是,有一点特殊的是,整数是通过字符串来实现的。例如:
> SET height 170
OK
> INCR height
(integer) 171
> DECR height
(integer) 170
incr和decr是专门为了处理整数而设计的指令,它们会将整数增加1或者减少1。如果增加或者减少其他数值的话,可以使用INCRBY和DECRBY指令。
Redis还支持一些其他的字符串指令,我们将它们总结在下表中。
| 指令 | 说明 |
|---|---|
| APPEND | 将一个字符串添加到另一个字符串的尾部。 |
| DECR | 整数的减法操作。 |
| DECRBY | 整数的减法操作。 |
| GET | 获得Key对应的Value元素。 |
| GETRANGE | 获得字符串的子串。 |
| GETSET | 设置字符串的值,并返回其旧值。 |
| INCR | 整数的加法操作。 |
| INCRBY | 整数的加法操作。 |
| INCRBYFLOAT | 浮点数的加法操作。 |
| MGET | 获取多个Key对应的Value元素。 |
| MSET | 设置多个Key对应的Value元素。 |
| MSETNX | 只有在所有Key不存在的情况下才设置多个Key对应的Value元素。 |
| PSETEX | 设置Key对应的Value元素和过期时间(Expiration Time)。 |
| SET | 设置Key对应的Value元素。 |
| SETEX | 设置Key对应的Value元素和过期时间(Expiration Time)。 |
| SETNX | 设置多个Key对应的Value元素。 |
| SETRANGE | 设置字符串某区域内的值。 |
| STRLEN | 计算字符串的长度。 |
2.2 字符串的内部实现
Redis字符串的实现非常简单。Redis的字符串被称为简单动态字符串,即SDS (Simple Dynamic String)。如下图所示,Redis的字符串存放在一片连续的内存区域中。字符串结构的头部是固定长度的头结构(sdshdr8,sdshdr16,sdshdr32,或者sdshdr64)。结构的主体部分存放的是字符串的内容,以'\0'结束。在头结构中,len字段表示了该字符串的长度。

图一 Redis字符串的结构图。
头结构sdshdr8,sdshdr16,sdshdr32和sdshdr64分别用于不同长度的字符串。下面给出了结构体sdshdr8的结构,当字符串变长且len字段不足以表示长度时,该字符串会被升级为sdshdr16。在sdshdr16结构体中len字段为双字节无符号整型uint16_t,而在sdshrd8结构体中len字段为单字节无符号整形uint8_t。提示:uint8_t和uint16_t为C语言标准库中定义的无符号双字节整型,类似的类型还有uint32_t,和uint64_t。
// Redis 5.0.8 版本
// Redis字符串的定义与实现在 src/sds.h 和 src/sds.c 文件中
typedef char *sds;
struct sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
...
3 链表类型
3.1 链表的基本操作
Redis的链表为双向链表。表中的元素按照插入链表的顺序排列。Redis支持在表头或者表尾插入。双链表的基础知识和工作原理可参考小水滴课程中的链表章节。
LPUSH和RPUSH命令分别在表头或者表尾插入链表。LPOP和RPOP命令分别从表头或者表尾删除一个元素,并将删除的元素返回。当插入新元素时,如果链表不存在的话,LPUSH和RPUSH会自动创建一个空的新链表。因此,Redis并没有创建链表命令。
> LPUSH nameList Bob
(integer) 1
> RPUSH nameList Alice
(integer) 2
> LLEN nameList
(integer) 2
> RPOP nameList
"Alice"
> LPOP nameList
"Bob"
上述操作首先创建一个空的链表nameList,并从表头插入字符串"Bob"。然后,再从表尾插入字符串"Alice"。此时,链表nameList的长度为2。最后,我们使用RPOP和LPOP分别从nameList的表尾和表头移除两个元素。
Redis还支持一些其他的链表指令,我们将它们总结在下表中。
| 指令 | 说明 |
|---|---|
| BLPOP | 从表头删除一个元素。如果链表为空,则删除操作被阻塞。 |
| BRPOP | 从表尾删除一个元素。如果链表为空,则删除操作被阻塞。 |
| BRPOPLPUSH | 从源链表的表尾删除一个元素,并将其插入到目标链表的表头。如果源链表为空,则操作被阻塞。 |
| LINDEX | 使用索引获取元素。 |
| LINSERT | 在指定元素之前或者之后插入新元素。 |
| LLEN | 获取链表中元素的个数。 |
| LPOP | 从表头删除一个元素。 |
| LPUSH | 从表头插入一个元素。 |
| LPUSHX | 只有当链表存在时才从表头插入元素。 |
| LRANGE | 获得链表中某一范围内的所有元素。 |
| LREM | 从链表中删除一个元素。 |
| LSET | 使用索引设置元素。 |
| LTRIM | 按照某一个范围剪切链表。 |
| RPOP | 从表尾删除一个元素。 |
| RPOPLPUSH | 从源链表的表尾删除一个元素,并将其插入到目标链表的表头。 |
| RPUSH | 从表尾插入一个元素。 |
| RPUSHX | 只有当链表存在时才从表尾插入元素。 |
3.2 链表的内部实现
Redis的链表是一个双向链表。链表的结构名为struct list,它有head和tail两个字段,分别指向表中的头节点和尾节点。len字段表示链表中元素的个数。链表中节点的结构为listNode。listNode有三个字段,prev指向前驱节点,next指向后继节点,value则表示当前节点的值。下图是包含了三个元素的Redis链表结构图。链表和链表节点的定义如下面的代码所示。
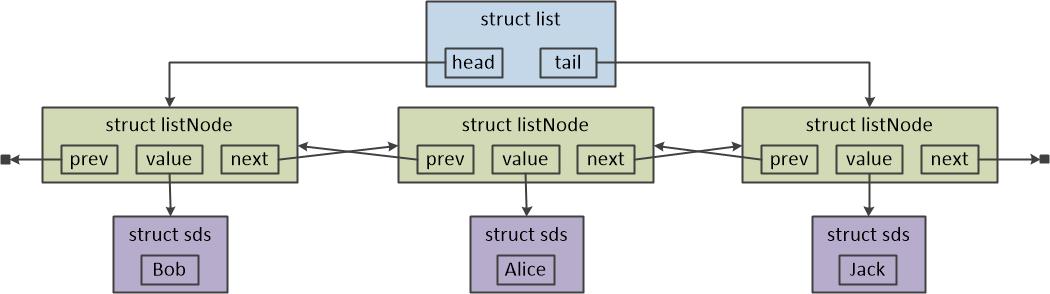
图二 Redis链表的结构图。
// Redis 5.0.8 版本
// Redis链表的定义和实现在 src/adlist.h 和 src/adlist.c 文件中
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct list {
listNode *head; // 指向表头的指针
listNode *tail; // 指向表尾的指针
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
4 哈希表类型
4.1 哈希表的基本操作
哈希表又被称为映射表(Map)或者字典(Dictionry)。实际上Redis就是一个大的哈希表;它存放了Key/Value的记录,并在此基础上添加了一些数据查询和数据处理的特性。
HSET,HDEL和HGET命令分别为哈希表添加记录,删除记录和查询记录。HMGET可以一次查询多条记录。如下所示:
> HSET priceMap book 10.99
(integer) 1
> HSET priceMap magazine 5.99 newspaper 1.99
(integer) 2
> HGET priceMap magazine
"5.99"
> HMGET priceMap book newspaper
1) "10.99"
2) "1.99"
> HLEN priceMap
(integer) 3
> HKEYS priceMap
1) "book"
2) "magazine"
3) "newspaper"
> HVALS priceMap
1) "10.99"
2) "5.99"
3) "1.99"
我们首先使用了HSET命令创建了一个哈希表priceMap,并添加了一条记录,book的价格为10.99圆。然后,我们再次使用HSET命令添加两条记录,magazine和newspaper的价格分别为5.99和1.99圆。最后,我们使用HGET和HMGET查询它们的价格。这里值得注意的是,Redis是使用字符串来表示价格(浮点数)的。HKEYS和HVALS命令可以查询哈希表中所有的Key和Value的值。
Redis还支持一些其他的哈希表指令,我们将它们总结在下表中。
| 指令 | 说明 |
|---|---|
| HDEL | 从哈希表中删除一个或者多个元素。 |
| HEXISTS | 判断一个元素是否存在于哈希表中。 |
| HGET | 获取哈希值对应的元素。 |
| HGETALL | 获取哈希表中所有的哈希值和对象。 |
| HINCRBY | 增加哈希值。 |
| HINCRBYFLOAT | 增加哈希值。 |
| HKEYS | 返回哈希表中所有的哈希值。 |
| HLEN | 返回哈希表中的元素个数。 |
| HMGET | 获取多个哈希值对应的元素。 |
| HMSET | 向哈希表添加/设置一个或者多个元素。 |
| HSET | 向哈希表添加/设置元素。 |
| HSETNX | 只有当哈希值不存在时才添加/设置元素。 |
| HSTRLEN | 获取字符串对象的长度。 |
| HVALS | 获取哈希表中所有的元素。 |
| HSCAN | 扫描哈希表。 |
4.2 哈希表的内部实现
Redis的哈希表的实现也较为简单。与传统的哈希表相比,一个明显的区别是Redis哈希表实际上包含了两个哈希表。同一个bucket中的数据由单链表相连。单链表的原理和实现细节可参考小水滴课程中的链表章节。
如下图所示,Redis哈希表的结构为struct dict,它包含了两个哈希表struct dictht。struct dictht实际上是一个传统的哈希表,它包含了一个struct dictEntry的指针数组,这个数组中的元素被称为bucket。每个bucket中的元素(struct dictEntry)由单链表相连(结构struct dictEntry中的next字段指向下一个struct dictEntry元素)。
Redis哈希表包含了两个哈希表的原因是,当向哈希表中添加或者删除元素时,Redis会根据存在元素的多少来动态调整整个哈希表的大小。一旦哈希表的大小变化了,所有元素对应的bucket就会做相应的改变/调整。这个调整对应bucket的过程被称为rehashing。当哈希表中元素较多时,rehashing是非常费时的,而Redis是单线程的进程。为了使rehashing的过程不阻塞Redis处理新的请求,Redis创建了两个哈希表,将rehashing的过程分步完成(不必一次完成)。当rehashing发生时,Redis逐步的将一个哈希表中的元素移至另一个哈希表中,并完成对该元素的rehashing。这种策略也被称为incremental rehashing。这种策略的缺点也很明显。当rehashing尚未完成之前,Redis需要查看两个哈希表,以确保结果的正确性。例如:Redis需要检查两个哈希表以确定一个元素是否存在。
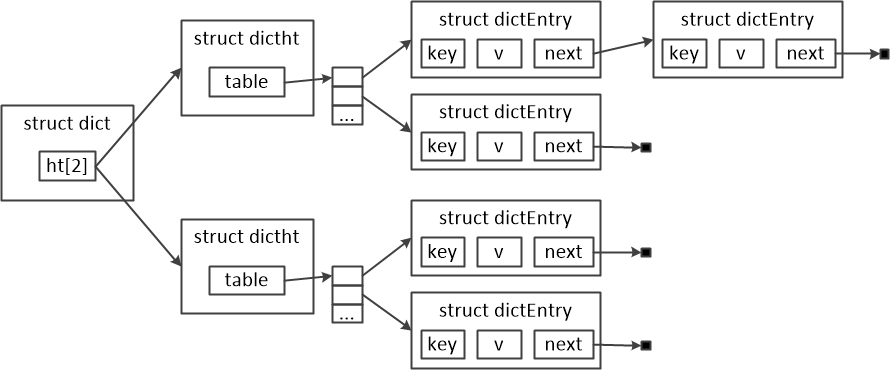
图三 Redis哈希表的结构图。
Redis中哈希表的结构定义如下。
// Redis 5.0.8 版本
// Redis哈希表的定义和实现在 src/dict.h 和 src/dict.c 文件中
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
5 集合类型(Set)
5.1 集合的基本操作
集合是一组无序的元素。Redis集合数据类型支持向集合添加、删除和测试某元素是否存在的操作。Redis集合不允许重复元素。如果向集合多次添加同一元素,则该集合只包含一个这样的元素。
SADD和SPOP命令向一个集合添加或者删除一个元素。如下所示:
> SADD nameSet Bob
(integer) 1
> SADD nameSet Alice
(integer) 1
> SADD nameSet Bob
(integer) 0
> SMEMBERS nameSet
1) "Bob"
2) "Alice"
我们使用了SADD创建了一个空的集合nameSet,并且向其添加了一个字符串"Bob"。然后,我们再次使用SADD向集合添加字符串"Alice"。最后,当我们再次向集合添加"Bob"时,集合并没有加入"Bob",因为它已经存在于集合中了。当我们使用SMEMBERS命令获取集合中所有的元素时,它返回了两个元素"Bob"和"Alice"。
Redis还支持一些其他的集合指令,我们将它们总结在下表中。
| 指令 | 说明 |
|---|---|
| SADD | 向集合添加新元素。 |
| SCARD | 获取集合中元素的个数。 |
| SDIFF | 返回第一个集合与其他集合的不同元素。 |
| SDIFFSTORE | 比较第一个集合与其他集合的不同元素,并将其存储在一个Key中。 |
| SINTER | 计算多个集合中的共同元素。 |
| SINTERSTORE | 计算多个集合中的共同元素,并将其存储在一个Key中。 |
| SISMEMBER | 判断元素是否在集合中。 |
| SMEMBERS | 返回集合中的所有元素。 |
| SMOVE | 将集合中的一个元素移至另一个集合。 |
| SPOP | 随机从集合中移除一个或者多个元素。 |
| SRANDMEMBER | 随机获取一个或者多个元素。 |
| SREM | 从集合中移除一个或者多个元素。 |
| SUNION | 计算多个集合的合集。 |
| SUNIONSTORE | 计算多个集合的合集,并将其存储在一个Key中。 |
| SSCAN | 扫描集合中所有元素。 |
5.2 集合的内部实现
虽然从概念上看,集合是一组无序的元素,然而,在实现中,Redis并没有完全遵从这个概念。在Redis内部,集合是由上述的哈希表或者有序数组实现的。当集合中的元素是整数时,Redis会使用intset数据结构保存这些元素。当集合中元素不是整数时,则使用哈希表来保存数据。我们已经在第四节中介绍了哈希表的内部实现,因此,在这里,我们仅介绍intset数据结构。
intset是一个动态的整型数组。在intset结构体的头部,字段length表示了后续数据的长度。contents字段是一个有序的整数序列。Redis保持数列有序的状态是为了提供更快的查找速度。如图四所示,在插入数字5之前,Redis将数列0,3,4,6,8,9有序的保存在intset中。当插入数字5时,Redis会使用二分查找算法(Binary Search Algorithm)查找新元素应该出现的位置。为了将新整数5插入序列,Redis会将大于5的数字向后移一位,以保持有序的状态。类似的,如果将数字5删除的话,所有大于5的数字将会往前移一位。当查找某一数字是否存在于集合中时,可以使用二分查找算法。
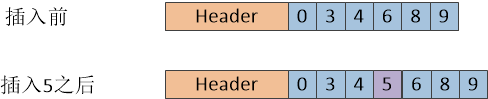
图四 Redis整数集合的结构图。
intset结构体的定义如下。
// Redis 5.0.8 版本
// Redis整型集合的定义和实现在 src/intset.h 和 src/intset.c 文件中。
// Redis集合的实现在src/t_set.c中。在此文件中可以查看Redis如何区分整型集合和哈希表集合的。
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
6 有序集合类型
6.1 有序集合的基本操作
有序集合是一组有序的元素。它与集合的区别是,从概念上看,有序集合保持元素之间的有序性。正是因为有序集合保持了元素的有序性,所以,插入、删除和查找元素都非常快。在有序集合中,每个元素都有一个分数(score),Redis使用这个分数为元素排序。元素按照增序排列,分数小的元素排在前面,分数大的元素排在后面。有序集合不允许重复元素,但是,多个不同的元素可以设置相同的分数。
ZADD和ZREM命令用于向有序集合添加和删除元素。如下所示:
> ZADD sortedSet 10 Bob
(integer) 1
> ZADD sortedSet 5 Alice 15 David
(integer) 2
> ZSCORE sortedSet David
"15"
> ZRANGE sortedSet 0 100
1) "Alice"
2) "Bob"
3) "David"
> ZREM sortedSet David
(integer) 1
在上面执行的命令中,我们首先创建了一个有序集合sortedSet,并添加一个字符串Bob,分数为10;随后,又添加了Alice和David,分数分别是5和15。然后,我们使用ZSCORE命令查询元素David的分数。ZRANGE命令查询分数在[0, 100]区间的所有元素。在我们的例子中,它们是Alice,Bob,和David。注意,它们是按照分数自低向高排列输出的。最后,我们使用ZREM命令删除了元素David。
Redis还支持一些其他的有序集合指令,我们将它们总结在下表中。
| 指令 | 说明 |
|---|---|
| BZPOPMIN | 获取一个或者多个分数最低的元素,如果有序集合为空,则操作被阻塞。 |
| BZPOPMAX | 获取一个或者多个分数最高的元素,如果有序集合为空,则操作被阻塞。 |
| ZADD | 向有序集合中添加新元素。 |
| ZCARD | 获得有序集合中元素的个数。 |
| ZCOUNT | 获取有序集合中分数在某一范围内的元素个数。 |
| ZINCRBY | 增加元素的分数。 |
| ZINTERSTORE | 计算多个有序集合的共同元素,并将其存储在一个Key中。 |
| ZLEXCOUNT | 计算某一范围内的元素个数。 |
| ZPOPMAX | 获取一个或者多个分数最高的元素。 |
| ZPOPMIN | 获取一个或者多个分数最低的元素。 |
| ZRANGE | 返回有序集合中元素的范围。 |
| ZRANGEBYLEX | 返回有序集合中元素的范围。 |
| ZREVRANGEBYLEX | 返回有序集合中元素的范围。 |
| ZRANGEBYSCORE | 返回有序集合中元素的范围。 |
| ZRANK | 获得元素的索引值。 |
| ZREM | 从有序集合中删除一个或者多个元素。 |
| ZREMRANGEBYLEX | 删除某一范围内的所有元素。 |
| ZREMRANGEBYRANK | 删除某一范围内的所有元素。 |
| ZREMRANGEBYSCORE | 删除某一范围内的所有元素。 |
| ZREVRANGE | 返回有序集合中元素的范围。 |
| ZREVRANGEBYSCORE | 返回有序集合中元素的范围。 |
| ZREVRANK | 获得元素的索引值。 |
| ZSCORE | 获得元素的分数。 |
| ZUNIONSTORE | 计算多个有序集合的合集,并将其存储在一个Key中。 |
| ZSCAN | 扫描一个有序集合。 |
6.2 有序集合的内部实现
有序集合的实现集合了哈希表和Skip List数据结构。哈希表保存了从元素到分数的映射。所以,当插入、删除和查询某一元素时,通过哈希表能够快速的得知该元素是否已存在。Skip List结构是使用链表实现的一种复杂结构,它的工作原理与平衡树非常相似。Skip List保持了元素之间按照分数排列的有序性。因此,当Redis收到ZRANGE或者类似的命令时,Redis能够快速的从Skip List中查找对应的分数。
简单的说,以下图为例,Skip List是一个多层结构,每一层由一个单向链表组成。最底层保存了Skip List结构包含的所有数据。每一个元素都有一定的概率出现在上一层。在图五中,假设这个概率固定为50%的话,在最底层包含了六个元素,分别是0,3,4,6,8,9。这六个元素都有50%的概率会出现在第一层(Level 1)中。所以,从概率学上看,第一层数据的个数是最底层数据个数的一半。假设数据0,6,9出现在第一层的话,那么,它们又有50%的概率出现在第二层(Level 2)。因此,假设数据0和9出现在第二层的话,如图五所示。
那么,因为在每一层中,数据都是按照大小顺序排列的,所以,当在查找某一个数据时,搜索是从最顶层开始的,逐层往下,直到找到目标为止。假设,搜寻目标是9的话,那么,在搜索完顶层(Level 2)后就能找到目标。假设搜寻目标是8的话,如图五中红色虚线箭头所示,当在顶层搜索时,发现下一个元素比目标元素大时,搜索则进入下一层,从当前元素开始继续查找。因此,搜索目标8的搜索路径是0->0->6->6->8。
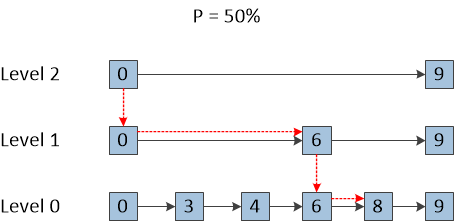
图五 Skip List的结构图。
7 Bitmaps类型
Redis是使用字符串来实现位图(Bitmaps)的。因此,它有时也被称为bit string(位串)。位图实际上是一串0或者1的字符串,Redis提供了按位操作(Bit-Oriented Operations)位串的命令。例如:
> SETBIT aBitString 10 1
(integer) 1
> GETBIT aBitString 10
(integer) 1
> GETBIT aBitString 11
(integer) 0
我们使用SETBIT首先创建了一个新的位串,并且将第10位的值设置为1。所以,在随后GETBIT的命令查询第10位的值时,Redis打印其值为1。但是,当查询第11位的值时,Redis返回0,这是因为创建的新位串的默认值是全0。
Redis还支持一些其他的位图指令,我们将它们总结在下表中。有关位操作的代码在src/bitops.c中。
| 指令 | 说明 |
|---|---|
| BITCOUNT | 计算字符串中1的个数。 |
| BITFIELD | 允许在字符串上执行多种位操作。 |
| BITOP | 两字符串之间做位操作。 |
| BITPOS | 在字符串中查找第一个0或者1。 |
| GETBIT | 查询位的值。 |
| SETBIT | 设置位的值。 |
8 HyperLogLogs类型
HyperLogLogs类型主要用于估计数据的个数,例如:一个"集合"中元素的个数(The Cardinality of a Set)。这里这个"集合"的概念是广义的。例如,这个"集合"可以是Redis中的链表、集合、有序集合、哈希表等。估计元素个数的方法有很多,最简单、最直观的方法是按照一定比例记录集合中元素的个数。但是,当集合非常大时,这种方法会消耗大量的内存。
HyperLogLogs是Redis为了解决这个问题而精心设计的算法。它能够仅使用1.5K字节的内存大小来估计包含109个数据的超大集合,并且标准错误率(Standard Error)在2%以内。它是如何做到的呢?我们先来看一个简单的例子。
> PFADD students Alice Bob David
(integer) 1
> PFCOUNT students
(integer) 3
> GET students
"HYLL\x01\x00\x00\x00\x03\x00\x00\x00\x00\x00\x00\x00U;\x80\a\x84N\xa9\x84\\\x0e"
我们首先使用PFADD命令创建一个新的HyperLogLogs类型,并加入三个字符串Alice, Bob和David。然后,我们使用PFCOUNT命令打印HyperLogLogs数据类型估计的、向其添加的元素的个数。在这个例子中,结果是3。最后,我们使用GET命令打印HyperLogLogs结构的内部表达。其实,HyperLogLogs是使用字符串实现的。
那么,HyperLogLogs的实现原理是怎样的呢?将HyperLogLogs的原理讲清楚需要很长的篇幅,并且要求读者有着很强的数学功底。在本文中,我们打算使用一个例子来大致的讲解一下其原理。对HyperLogLogs的理论细节和数学推导感兴趣的读者可以参考于2007年发表的论文。
P. Flajolet, E. Fusy; O. Gandouet, and F. Meunier. "HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm". In Analysis of Algorithms, pages 127-146, 2007.
我们将从抛硬币的例子开始。抛硬币的游戏是将一个硬币抛向空中,在落地时,硬币正面朝上的概率是50%,硬币背面朝上的概率也是50%。那么,假设我们做一组实验,这组实验抛十次硬币,使用1表示正面朝上,使用0表示背面朝上,那么,一组实验的结果可能是"0001111111"。这个结果代表前三次的实验结果是背面朝上,后七次的实验结果是正面朝上。
那么,我们一次又一次的重复上述的实验,我们做多少次实验才能得到一组结果,前五次全部背面朝上呢(后五次实验可以是任意结果)?如果每组实验都是独立完成的话,答案是:约25次。换句话说,如果实验从第一次开始,一直做到我们得到一组结果,前五次全部背面朝上的实验为止,那么,我们可以估计我们一共需要做25组实验。那么,如果希望得到一组实验的结果是前6次实验都是背面朝上呢?我们可以估计需要做26组实验。
HyperLogLogs使用了类似的原理。Redis首先在对象上调用哈希函数,将对象标准化为一个位串。Redis假设这个位串的值是均匀分布的(Under Uniform Distribution)。然后,使用这个位串(哈希值)的前缀0(Leading Zeros)的长度来估计有多少对象已被加入到一个集合之中。例如,从加入第一个对象开始,HyperLogLogs跟踪每一个对象的哈希值,并记录最长的前缀0的位数。如果最长前缀0的个数是5的话,则我们可以大致认为有25个对象加入了HyperLogLogs。如果记录中最长的前缀0的个数是6的话,则我们可以大致认为有26个对象加入了HyperLogLogs。
按照这个原理,HyperLogLogs对象只需要1.5K字节的内存来估计109个数据的超大集合。HyperLogLogs相关的实现在src/hyperloglog.c中。
HyperLogLogs解决的是数据库领域的一个基本问题:Cardinality Estimation。集合中元素个数和元素的值的分布对于数据库查询优化至关重要。值得注意的是,HyperLogLogs的实现并不是完美无瑕的。HyperLogLogs的原理是建立在对象的哈希值遵循均匀分布的假设上的。然而,这个假设在实际应用中是否成立,尚不清楚。因为对象的哈希值的分布依赖于哈希函数的实现和对象的取值分布。在HyperLogLogs提出来之后,也有学者对其做了改进。如果读者对这个领域或者类似问题感兴趣的话,可以给我们留言,我们会分享几篇经典的论文。
9 总结
本章介绍了Redis支持的几种数据类型。数量的掌握了它们的使用方法就能完成一些基本的Redis应用程序了。在介绍了数据结构的基本操作之后,我们还简略的讲解了这些数据结构的内部实现。这些知识有利于开发人员进一步理解Redis整个系统的运行原理和方式。有了本章作为基础,我们将在随后的章节中进一步深入Redis系统。
上一章
下一章
注册用户登陆后可留言