- 一、前言(Preface)
- 二、标题与作者列表(Title and Author List)
- 三、摘要(Abstract)
- 四、概述(Introduction)
- 五、相关研究(Related Work)
- 六、基础知识(Preliminaries)
- 七、新模型和新概念(Model and Concept)
- 八、设计与实现(Design and Implementation)
- 九、分析(Analysis)
- 十、实验结果(Experimental Validation)
- 十一、总结及未来计划(Conclusion and Future Work)
- 十二、致谢(Acknowledgement)
- 十三、参考文献列表(Bibliography)


第八章 设计与实现 (Design and Implementation)
本章节是整篇文章最核心的部分。前面所讨论的章节,例如概述(Introduction),相关研究(Related Work), 新模型/新概念(Model/Concept)等, 都是为了引出新方法的设计与实现和突出新方法的新颖性和独特性的。 在本章我们着重介绍如何构思和表述设计和实现章节。每篇论文设计与实现章节的内容各不相同,下面是三种常见于各种论文中的方法,即自顶向下法, 由浅入深法和抛砖引玉法。
8.1. 自顶而下(Top-Down)法
自顶而下的方法是一种常见的方法。该方法从解决方案的整体出发,将各个部分以模块的形式组织在一次。该方法首先给读者一个宏观的介绍,然后, 再逐步细化各个部分的内容。基于此方法的论文,一般以解决方案框架(Framework)或者整体介绍(Overview)入手,将其独立设置成一个子章节, 或者出现在第一个子章节之前。然后,其他各个部分自成一个子章节,或者以某种逻辑将几个部分安排在一个子章节中。
例:
本例给出的这篇论文在第二章使用了自顶而下的方法。该论文将相关研究章节安排在实验章节之后,因为Skyline Query是在该领域内较为熟知的研究问题。 如图1所示,作者在第一个子章节(2.1)中,首先介绍了新方法的输入与输出,以及方法内部的三个步骤,并且简洁的阐述了每一个步骤所使用的概念。 换句话讲,这个子章节讲述了新方法的整体流程。 然后在第二个子章节(2.2)着重介绍新方法的第一个步骤,即寻找MBR集合中的Skyline元素;在第三个子章节(2.3)中介绍了第二个步骤, 即多个依赖组的生成方法。在图1中,明确标识了后续描述算法在新方法中的位置,所以,依据此图,读者能够清晰的看到整个设计章节的组织结构。 因为第三步骤非常简单,所以,在第二章的最后,作者仅用了一小自然段阐述第三个步骤的内容,并再次快速总结了整个新方法的处理流程。
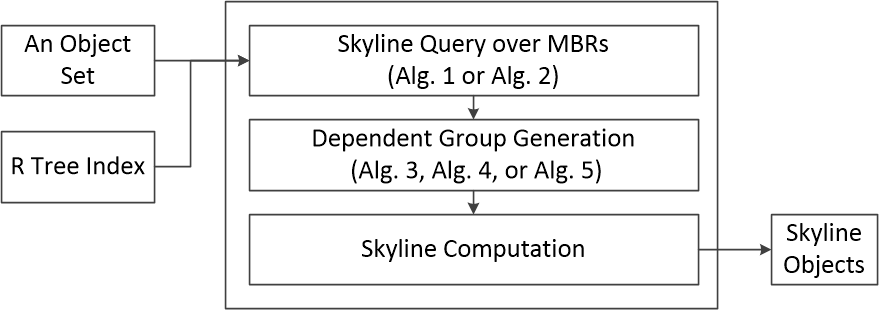
图 1. 自顶而下法。
本例引用自
Ji Zhang, Wenlu Wang, Xunfei Jiang, Wei-Shinn Ku, and Hua Lu. An MBR-Oriented Approach for Efficient Skyline Query Processing. In Proceedings of the 35th IEEE International Conference on Data Engineering (ICDE), Macau SAR, China, April 2019.
8.2. 由浅入深法
由浅入深的方法遵循从易到难的思路,即先解决一个相对简单的问题,然后逐步增加问题的复杂度和难度, 直到完全解决所研究的问题为止。有时,某些论文所研究的问题比较复杂,或者所提出的新方法比较复杂, 如果直接给出完整的解法,读者可能会比较难以接受。由浅入深法非常适用于这种情况。 论文可以从一个较为容易理解的场景,或者贴近生活的用例入手,逐步增加难度,并且使用例子辅助读者理解。
以下论文在设计章节(5.3)中,使用了由浅入深法证明一个重要的概念Pruning Region。 整个章节的核心就是提出这个概念(Theorem 2)和证明由这个概念得出的一个规则。此例仅仅是为了介绍由浅入深的用法。如果对其证明细节感兴趣, 可参考论文原文。
因版权原因,请登陆后阅读由浅入深法的例子。
8.3. 抛砖引玉法
抛砖引玉法的思路是以问题为驱动力;先抛出一个问题,再解决这个问题。这个问题可能存在于已经发表的方法中,也可能是一个新问题。 而抛出这个问题是为了引出论文将要提出的新方法。
以下用例引用的论文使用了抛砖引玉法来提出两个数据划分的方法。这两种方法严格控制每个划分中数据量的大小,以加快数据分割后的并行计算的处理速度。 读者如对其论述过程感兴趣,可参考论文原文。
例:
经作者观察,使用经典算法MaxSum和MaxDist划分数据的结果并不令人满意。这两个方法都同时进行数据划分和数据过滤。 在处理过程中,某些区域的数据被过滤的较多,而另一些区域被过滤的较少。 这就造成了在数据过滤切分之后数据分布不均匀的情况。然而,在后续的并行计算中每个分区被独立处理, 整个并行计算的用时取决于处理拥有最多数据的分区的时间。为了改进数据过滤和划分的过程,并提出新的方法, 该论文按照如下逻辑组织了这个子章节内容。
首先,论文做了一个简单的实验(Preliminary Experiments),使用一个表格展示了经MaxSum 和MaxDist处理之后,各分区包含数据的个数。 这个实验结果证明了作者的一个观察,即使用MaxSum 和MaxDist会造成数据分布不均匀的问题。 然后,论文阐述了一个基本的并行计算的理论观点,整个并行计算的用时由最慢的那个处理程序决定。 所以,论文指出需要一个更优的数据划分的方法来改进这个并行计算的过程。
在准备提出新方法之前,经作者的分析,提出新方法最根本的目的其实不是解决数据分布不均的问题。其根本问题是那个最“胖”分区包含了太多数据。 所以,第一个新方法着重关注最“胖”的那个分区,将数据过滤重点放在这个最``胖''的分区上。 但是,当前最“胖”的分区并不一定是最后那个最“胖”的分区。提前将重心放在当前最“胖”的分区并不一定能得到最好的结果。 所以,论文还提出了第二个新方法,将数据过滤的重点按照“胖”“瘦”比例分配到各个分区上。
值得注意的是,上述实验只是为了暴露MaxSum和MaxDist存在问题。但实验结果不能证明新方法优于MaxSum和MaxDist。 这是需要在后续实验结果章节中给出定量的分析,以作为前后呼应。
本例引用自 Ji Zhang, Xunfei Jiang, Wei-Shinn Ku, and Xiao Qin. Efficient parallel skyline evaluation using MapReduce.
IEEE Transactions on Parallel and Distributed Systems (IEEE TPDS), Vol. 27, Issue. 7, pp. 1996-2009, 2016.
实战篇
实战篇根据笔者多年论文写作经验和审稿工作,总结了在论文撰写过程中的实战经验,并将其汇总于多个主题之中。笔者还从上千篇2018年发表的顶级会议和期刊论文中筛选了一些优秀的范例,以帮助读者更好地理解本篇中描述的写作技巧和细节。
由于论文所论述的问题以及应用场景不同,在论文中,作者可能会使用不同的写作方法。笔者需要指出的是,本文总结的是笔者对于论文写作的理解与经验,若读者有不同的方法或者实战经验,欢迎来信与笔者详细讨论。笔者在写作过程中,兢兢业业,力求完整无瑕。然而由于笔者水平有限,文中难免出现疏忽、遗漏或者错误之处,尚期读者不吝指正。若对本文有任何的建议和意见,请与我们联系。
若读者对实战篇的内容感兴趣,请登录后/免费注册后阅读全部内容。
上一章
下一章
这篇文章很有用。
- jzz0014 创建于 2019-08-25 08:17:50
注册用户登陆后可留言