- 一、前言
- 二、Java生态系统
- 三、Java程序的基本结构
- 四、数据类型与变量
- 五、操作符与运算
- 六、表达式(Expression)与语句(Statement)
- 七、类型转换与提升(Type Conversion and Promotion)
- 八、if语句(If Statement)
- 九、switch语句
- 十、while语句和do-while语句
- 十一、for循环语句
- 十二、break语句和continue语句
- 十三、Java关键字 (Java Keywords)
- 十四、Java小测验(一)
- 十五、Java小测验(二)
- 十六、面向对象程序设计
- 十七、接口(Interface)
- 十八、标注(Annotation)
- 十九、继承(Inheritance)
- 二十、Java语言为什么不支持多重继承(Multi-Inheritance )
- 二十一、多态(Polymorphism)
- 二十二、多态(Polymorphism)的实现与Virtual Table
- 二十三、与命名冲突相关的五个重要概念
- 二十四、函数签名相等性(Override-Equivalent Signatures)
- 二十五、Try语句
- 二十六、Java异常类型
- 二十七、装箱转换(Boxing)和拆箱转换(Unboxing)
- 二十八、枚举
- 二十九、数组
- 三十、字符串类(String)
- 三十一、对象释放过程(Object Finalization)
- 三十二、对象复制(Object Cloning)
- 三十三、对象相等性(Object Equality)
- 三十四、包(Package)与模块(Module)
- 三十五、反射机制(Reflection)
- 三十六、可变参数(Varargs)和堆污染(Heap Pollution)
- 三十七、Java小测验(六)
- 三十八、Java小测验(七)
- 三十九、Java并发编程概述
- 四十、Java线程的创建和销毁
- 四十一、Java多线程的复杂性
- 四十二、Java 线程同步与关键字synchronized
- 四十三、Wait和Notify机制
- 四十四、原子类与并发容器
- 四十五、Java锁(Lock)与信号量(Semaphore)
- 四十六、Java异步执行机制和Callable/Future接口
- 四十七、线程池(Thread Pool)和ExecutorService接口
- 四十八、CountDownLatch, CyclicBarrier, Phaser 和 Exchanger
- 四十九、关键字volatile
- 五十、关键字final
- 五十一、Java虚拟机概述
- 五十二、Java虚拟机初始化过程
- 五十三、Java类加载器(Class Loader)
- 五十四、Java类文件结构(Structure of .class File)
- 五十五、Java虚拟机的内存布局
- 五十六、Java虚拟机的垃圾回收机制(Garbage Collection)
- 五十七、Java虚拟机的解释器与指令集(JVM Interpreter and Instruction Set)
- 五十八、Java虚拟机的解释器与指令集之函数调用(JVM Interpreter and Function Call)
- 五十九、invokedynamic指令与Lambda表达式的实现
- 六十、Java虚拟机调优(JVM Tuning)
- 六十一、Java泛型编程(Java Generics)
- 六十二、Java泛型类(Java Generic Classes)
- 六十三、类型擦除(Type Erasure)
- 六十四、Lambda表达式
- 六十五、Method Reference表达式
- 六十六、Functional Interface
- 六十七、Apache Maven
- 六十八、Gradle
- 六十九、Java编程规范
- 七十、Checkstyle
- 七十一、PMD
- 七十二、日志(Logging)
- 七十三、SLF4J日志库
- 七十四、单元测试框架JUnit
- 七十五、Mocking框架MMockito
- 七十六、Jackson之一
- 七十七、Jackson之二
- 七十八、Jackson之三
- 七十九、Jackson之四
- 八十、数据库应用程序(Database Applications)
- 八十一、JDBC(Java Database Connectivity)
- 八十二、JDBC基本使用方法
- 八十三、Statement接口的基本使用方法
- 八十四、PreparedStatement接口的基本使用方法
- 八十五、CallableStatement接口的基本使用方法
- 八十六、事务处理(Transaction Processing)
- 八十七、"大"对象Blob与Clob
- 八十八、"数据源(DataSource)与数据库连接池(DB Connection Pool)
- 八十九、"JDBC与Spreadsheet文档、XML文档
- 九十、Fail-Fast迭代器和Fail-Safe迭代器
- 九十一、Java标准库-容器(Collection)
- 九十二、Java标准库-链表(List)
- 九十三、Java标准库-集合(Set)
- 九十四、Java标准库-栈(Stack)
- 九十五、Java标准库-队列(Queue)
- 九十六、Java标准库-映射(Map)
第九十一章 Java标准库-集合(Set)
1 概述
集合(Set)是一种常见的数据结构。一个集合对象可以包含多个不重复的对象。有些集合允许包含空引用(null),而有些集合则不允许空引用。集合并不维护元素之间的次序;因此,集合中元素的次序或者排列由具体的实现决定(Implementation-dependent)。
集合、链表和数组是三种最为常见的数据结构。链表可以包含重复的元素,并且保持元素之间的顺序;而集合并不支持这两点。所以,集合的应用场景与链表的应用场景有所不同。正是因为集合不需要保存元素的次序,集合能够提供更高效的平均查找数度。
Java标准库中包含的Set相关类的结构如下图所示。
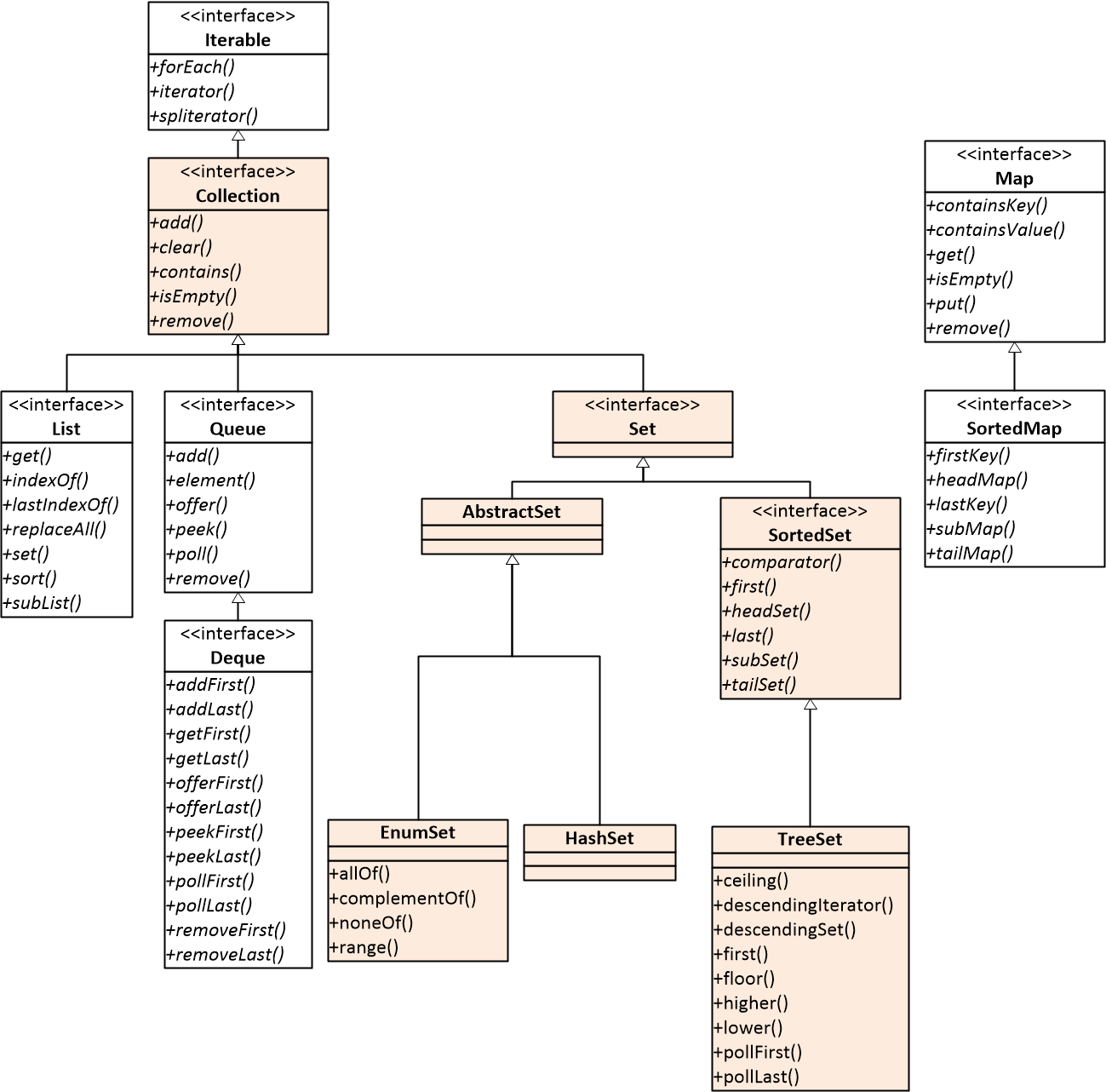
图一 Set相关类结构图
2 集合的接口
集合的接口和操作相对简单。集合的接口声明在java.util.Set接口中。Set接口继承自java.util.Collection接口,因此,集合也是一种容器。
2.1 添加和删除元素
Set接口提供了add()、addAll()、remove()和removeAll()接口用于向集合添加和删除元素。它们的使用方法和链表或者其他容器相同。
Set<Integer> setOfIntegers = new TreeSet<Integer>();
setOfIntegers.add(1); // 添加元素1
setOfIntegers.add(2); // 添加元素2
setOfIntegers.remove(1); // 删除元素1
2.2 查找元素
contains()和containsAll()方法用于检查元素是否存在于集合对象之中。
Set<Integer> setOfIntegers = new TreeSet<Integer>();
setOfIntegers.add(1); // 添加元素1
setOfIntegers.add(2); // 添加元素2
System.out.println(setOfIntegers.contains(1)); // 打印true,因为元素1存在于setOfIntegers集合中
2.3 集合中元素个数
isEmpty()和size()分别用于检查集合是否为空集合和集合中元素的个数。
Set<Integer> setOfIntegers = new TreeSet<Integer>();
setOfIntegers.add(1); // 添加元素1
setOfIntegers.add(2); // 添加元素2
System.out.println(setOfIntegers.isEmpty()); // 打印false,因为setOfIntegers不为空
System.out.println(setOfIntegers.size()); // 打印2,因为setOfIntegers有两个元素
2.4 创建不可变更集合(Unmodifiable Set)
Set接口提供了一系列的of()方法,用于创建不可变更的集合对象。
Set<Integer> setOfOneInteger = Set.of(1); // 创建包含一个元素的集合对象
Set<Integer> setOfTwoIntegers = Set.of(1, 2); // 创建包含两个元素的集合对象
...
2.5 遍历集合中的元素
Set接口的iterator()方法创建一个Iterator对象,用于遍历集合中每一个元素。
Iterator<Integer> it = setOfIntegers.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
Set接口继承了Collection接口中的stream()方法,所以,开发人员也可以使用Stream对象来遍历所有的元素。
Stream<Integer> stream = setOfIntegers.stream();
stream.forEach(x->System.out.println(x));
2.6 转换成数组对象
toArray()可以将集合对象转换成数组对象。生成的数组对象包含集合中所有的元素。
Integer[] allElements = setOfIntegers.toArray(Integer::new);
2.7 并发保护
大多数Set的实现并不提供并发保护。因此,当在多线程环境中使用EnumSet、HashSet或者TreeSet时,可以通过Collections类的方法创建出具备并发保护的Set对象。
Set<MyEnum> synchronizedEnumSet = Collections.synchronizedSet(EnumSet.noneOf(MyEnum.class));
Set<Integer> synchronizedSet = Collections.synchronizedSet(new HashSet<Integer>());
SortedSet<Integer> synchronizedSortedSet = Collections.synchronizedSortedSet(new TreeSet());
3 有序集合的接口
在上述的集合接口之上,java.util.SortedSet声明了有序集合的接口。SortedSet接口继承自Set接口,所以,SortedSet支持所有Set接口的操作和方法。
为了保持集合中元素的顺序,SortedSet需要使用Comparator对象来比较对象的大小,用以决定对象的顺序。在默认情况下,如果开发人员没有指定Comparator对象时,SortedSet会使用对象之间的自然顺序(Natural Ordering)。比如,Integer对象之间的自然顺序是它们整数值的顺序。
集合中每个对象都必须是可比较的,而且比较的顺序需要保持一致,否则有序集合不能确保元素的顺序。
SortedSet接口的iterator()方法返回的Iterator对象会按照元素的大小,从小到大依次访问每一个元素。
2.1 有序集合的最大、最小元素
既然元素之间有了顺序,那么,集合中就会存在最大元素和最小元素。first()方法可用于获取最小元素;last()方法可用于获取最大元素。
SortedSet<Integer> setOfIntegers = new TreeSet<Integer>();
setOfIntegers.add(1); // 添加元素1
setOfIntegers.add(2); // 添加元素2
System.out.println(setOfIntegers.first()); // 打印最小元素1
System.out.println(setOfIntegers.last()); // 打印最大元素2
2.2 获得有序集合的子集
有了一组有序的元素之后,我们可以根据它们的顺序,获取其子集合。subSet()方法指定了有序子集合的起始值和终止值。headSet()方法返回的子集合包含小于指定终止值的所有元素。tailSet()方法返回的子集合包含了大于指定起始值的所有元素。
SortedSet<Integer> setOfIntegers = new TreeSet<Integer>();
setOfIntegers.add(1); // 添加元素1
setOfIntegers.add(2); // 添加元素2
setOfIntegers.add(3); // 添加元素3
setOfIntegers.add(4); // 添加元素4
System.out.println(setOfIntegers.subSet(1, 3)); // 包含元素1和2
System.out.println(setOfIntegers.headSet(3)); // 包含元素1和2
System.out.println(setOfIntegers.tailSet(3)); // 包含元素3和4
4 集合的实现
4.1 java.util.AbstractSet
AbstractSet提供了实现集合java.util.Set接口的一些必要内容。AbstractSet是一个抽象类,所以它不能实例化。EnumSet、HashSet和TreeSet都继承自AbstractSet。
4.2 java.util.EnumSet
EnumSet是一种特殊的集合。它只能包含枚举值。EnumSet内部使用bit vector实现;它通过"位操作"提供了较高的性能和空间使用率。EnumSet不能存放null,否则会抛出NullPointerException异常。
EnumSet提供了一些有用的方法,帮助开发人员快速的创建集合对象。例如:allOf()方法可以根据给定的枚举类型创建一个包含所有枚举值的集合。
public enum Numbers {
ONE, TWO, THREE
};
EnumSet<Numbers> set = EnumSet.allOf(Numbers.class); // 创建了包含ONE、TWO、THREE的集合
如何希望创建一个空集合的话,可以使用noneOf()方法。
EnumSet<Numbers> set = EnumSet.noneOf(Numbers.class); // 创建了一个空集合
当一个集合对象包含了一些枚举值时,complementOf()方法可用于查询哪些枚举值不在这个集合中。
// Numbers枚举包含三个值
// 创建了一个空集合
EnumSet<Numbers> set = EnumSet.noneOf(Numbers.class);
// 添加一个枚举值
set.add(Numbers.ONE);
// complement集合包含TWO和THREE,因为这两个枚举值不在set对象中。
EnumSet<Numbers> complement = EnumSet.complementOf(set);
接下来我们介绍一些EnumSet的实现细节。EnumSet是一个抽象类;Java标准库提供了两个具体的实现java.util.RegularEnumSet和java.util.JumboEnumSet。在使用noneOf()或者allOf()创建EnumSet对象时,如果枚举值的个数不超过64个,Java标准库会使用RegularEnumSet。否则,会使用JumboEnumSet,如下面的代码所示。
在EnumSet中,成员变量elementType表示的是枚举类;universe数组则保存着该枚举类所有的枚举值。
// OpenJDK 15
package java.util;
public abstract class EnumSet<E extends Enum<E>> extends AbstractSet<E>
implements Cloneable, java.io.Serializable
{
final transient Class<E> elementType;
final transient Enum<?>[] universe;
...
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {
Enum<?>[] universe = getUniverse(elementType);
if (universe == null)
throw new ClassCastException(elementType + " not an enum");
if (universe.length <= 64)
return new RegularEnumSet<>(elementType, universe);
else
return new JumboEnumSet<>(elementType, universe);
}
...
}
RegularEnumSet类使用一个long类型的成员变量保存集合中的枚举值。因为long类型的变量有64位,所以,它能够最多表达64个不同的枚举值。JumboEnumSet则使用了一个long类型的数组。elements[0]表示第0-63个枚举值;elements[1]表示第64-127个枚举值,以此类推。其代码如下所示。
// OpenJDK 15
package java.util;
class RegularEnumSet<E extends Enum<E>> extends EnumSet<E> {
private long elements = 0L;
...
}
class JumboEnumSet<E extends Enum<E>> extends EnumSet<E> {
private long elements[];
...
}
在RegularEnumSet类和JumboEnumSet类中,当向集合添加新元素时,只需要将相应的位设置为1即可。
// OpenJDK 15
package java.util;
class RegularEnumSet<E extends Enum<E>> extends EnumSet<E> {
...
public boolean add(E e) {
typeCheck(e);
long oldElements = elements;
elements |= (1L << ((Enum<?>)e).ordinal());
return elements != oldElements;
}
...
}
class JumboEnumSet<E extends Enum<E>> extends EnumSet<E> {
...
public boolean add(E e) {
typeCheck(e);
int eOrdinal = e.ordinal();
int eWordNum = eOrdinal >>> 6;
long oldElements = elements[eWordNum];
elements[eWordNum] |= (1L << eOrdinal);
boolean result = (elements[eWordNum] != oldElements);
if (result)
size++;
return result;
}
...
}
4.3 java.util.HashSet
HashSet类使用了哈希表(Hash Table)来实现Set接口。在OpenJDK中,HashSet类使用了HashMap管理元素。HashSet没有实现SortedSet接口,所以,在遍历HashSet对象中的元素时,HashSet并不能确保元素的有序性。在HashSet中,元素的顺序可能随时发生变化。HashSet可以包含空引用元素null。
HashSet的操作与Set接口提供的操作基本相同。所以,我们省略了HashSet的操作介绍和用例,直接介绍它的内部实现。首先,HashSet类声明了成员变量map,用于保存对象。map的类型是HashMap<E, Object>。HashMap的实现细节可参考这里。
// OpenJDK 15
package java.util;
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map;
...
}
实际上,HashSet只使用了HashMap的键(Key),而没有使用值(Value)。值都是使用了一个Object对象PRESENT。
// OpenJDK 15
package java.util;
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
...
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public int size() {
return map.size();
}
...
}
4.4 java.util.TreeSet
TreeSet继承自AbstractSet;实现了Set和SortedSet接口。TreeSet在内部使用了TreeMap来保存元素,能够确保元素的有序性。因为TreeSet使用了TreeMap,所以,它的增添元素add()方法、删除元素remove()方法和查找元素contains()方法能够在log(n)的时间内完成。
TreeSet声明了一个NavigableMap类型的成员变量m,用于保存元素。TreeSet只使用了NavigableMap的键(Key);未使用值(Value)。值部分使用PRESENT对象填充。
// OpenJDK 15
package java.util;
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
private transient NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
...
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<>());
}
...
}
所以,在TreeSet上增加元素、删除元素和查找元素实际上是在NavigableMap上操作这些元素。
// OpenJDK 15
package java.util;
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
...
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
public boolean contains(Object o) {
return m.containsKey(o);
}
public int size() {
return m.size();
}
...
}
5 小结
本章介绍了集合Set的接口和使用方法。和List相似,Set也是一个常用的数据结构。但是,不同的是,Set不能确保元素的顺序,也不能包含重复的元素。有的集合可以包含null;有的则不行。Java标准库中提供了三种常用的集合实现。EnumSet专门用于包含枚举元素。HashSet使用了哈希表,提供快速的元素增、删和查询操作。但是HashSet不能保存元素的顺序。HashTree使用了TreeMap,提供有序集合的功能。
上一章
下一章
注册用户登陆后可留言