- 一、前言
- 二、Java生态系统
- 三、Java程序的基本结构
- 四、数据类型与变量
- 五、操作符与运算
- 六、表达式(Expression)与语句(Statement)
- 七、类型转换与提升(Type Conversion and Promotion)
- 八、if语句(If Statement)
- 九、switch语句
- 十、while语句和do-while语句
- 十一、for循环语句
- 十二、break语句和continue语句
- 十三、Java关键字 (Java Keywords)
- 十四、Java小测验(一)
- 十五、Java小测验(二)
- 十六、面向对象程序设计
- 十七、接口(Interface)
- 十八、标注(Annotation)
- 十九、继承(Inheritance)
- 二十、Java语言为什么不支持多重继承(Multi-Inheritance )
- 二十一、多态(Polymorphism)
- 二十二、多态(Polymorphism)的实现与Virtual Table
- 二十三、与命名冲突相关的五个重要概念
- 二十四、函数签名相等性(Override-Equivalent Signatures)
- 二十五、Try语句
- 二十六、Java异常类型
- 二十七、装箱转换(Boxing)和拆箱转换(Unboxing)
- 二十八、枚举
- 二十九、数组
- 三十、字符串类(String)
- 三十一、对象释放过程(Object Finalization)
- 三十二、对象复制(Object Cloning)
- 三十三、对象相等性(Object Equality)
- 三十四、包(Package)与模块(Module)
- 三十五、反射机制(Reflection)
- 三十六、可变参数(Varargs)和堆污染(Heap Pollution)
- 三十七、Java小测验(六)
- 三十八、Java小测验(七)
- 三十九、Java并发编程概述
- 四十、Java线程的创建和销毁
- 四十一、Java多线程的复杂性
- 四十二、Java 线程同步与关键字synchronized
- 四十三、Wait和Notify机制
- 四十四、原子类与并发容器
- 四十五、Java锁(Lock)与信号量(Semaphore)
- 四十六、Java异步执行机制和Callable/Future接口
- 四十七、线程池(Thread Pool)和ExecutorService接口
- 四十八、CountDownLatch, CyclicBarrier, Phaser 和 Exchanger
- 四十九、关键字volatile
- 五十、关键字final
- 五十一、Java虚拟机概述
- 五十二、Java虚拟机初始化过程
- 五十三、Java类加载器(Class Loader)
- 五十四、Java类文件结构(Structure of .class File)
- 五十五、Java虚拟机的内存布局
- 五十六、Java虚拟机的垃圾回收机制(Garbage Collection)
- 五十七、Java虚拟机的解释器与指令集(JVM Interpreter and Instruction Set)
- 五十八、Java虚拟机的解释器与指令集之函数调用(JVM Interpreter and Function Call)
- 五十九、invokedynamic指令与Lambda表达式的实现
- 六十、Java虚拟机调优(JVM Tuning)
- 六十一、Java泛型编程(Java Generics)
- 六十二、Java泛型类(Java Generic Classes)
- 六十三、类型擦除(Type Erasure)
- 六十四、Lambda表达式
- 六十五、Method Reference表达式
- 六十六、Functional Interface
- 六十七、Apache Maven
- 六十八、Gradle
- 六十九、Java编程规范
- 七十、Checkstyle
- 七十一、PMD
- 七十二、日志(Logging)
- 七十三、SLF4J日志库
- 七十四、单元测试框架JUnit
- 七十五、Mocking框架MMockito
- 七十六、Jackson之一
- 七十七、Jackson之二
- 七十八、Jackson之三
- 七十九、Jackson之四
- 八十、数据库应用程序(Database Applications)
- 八十一、JDBC(Java Database Connectivity)
- 八十二、JDBC基本使用方法
- 八十三、Statement接口的基本使用方法
- 八十四、PreparedStatement接口的基本使用方法
- 八十五、CallableStatement接口的基本使用方法
- 八十六、事务处理(Transaction Processing)
- 八十七、"大"对象Blob与Clob
- 八十八、"数据源(DataSource)与数据库连接池(DB Connection Pool)
- 八十九、"JDBC与Spreadsheet文档、XML文档
- 九十、Fail-Fast迭代器和Fail-Safe迭代器
- 九十一、Java标准库-容器(Collection)
- 九十二、Java标准库-链表(List)
- 九十三、Java标准库-集合(Set)
- 九十四、Java标准库-栈(Stack)
- 九十五、Java标准库-队列(Queue)
- 九十六、Java标准库-映射(Map)
第五十一章 Java虚拟机的内存布局
1 概述
当Java虚拟机运行时,所有的数据都是放在内存中的。这些数据包括程序创建出来的对象和支持Java虚拟机运行的数据。虽然,Java虚拟机的标准文档并未规定对象如何管理,Java虚拟机各组件之间如何协调工作,但是,绝大部分Java虚拟机的实现都会按照如下的方式组织和管理内存数据。因此,本章将详细介绍这种内存管理方法。请注意,如果读者在阅读Java虚拟机某个版本的具体实现时,发现与本文描述的存在差异的话,这个是正常的,毕竟Java虚拟机标准并未给出任何限制,各大厂商有足够的自由去选择实现的方法。
2 内存布局(Memory Layout)
总的来说,Java虚拟机的内存可大致分为三类:堆区域(Heap Area)、非堆区域(Non-Heap Area)和用于其他用途的区域。
- 堆区域(Heap Area)存放着在Java虚拟机运行时动态创建的数据,例如:Java虚拟机创建的对象实例,应用程序创建的对象实例等。堆区域是在Java虚拟机启动时创建出来的。它的大小可随着需要增长或缩小。在Java虚拟机启动时,堆的大小由参数-Xms决定,堆的最大大小由参数-Xmx决定。
- 非堆区域(Non-Heap Area)是在Java虚拟机启动时创建的,用于保存不常变化的数据,例如:类的常量池,类的代码数据,字符串等。常见的Permanent Generation数据,或者Metaspace区域(从Java 8起,Permanent Generation由Metaspace取代)就属于非堆区域。从名字上可以看出,Permanent Generation或者Metaspace是用于存放应用程序的元数据,这些数据在程序运行的过程中不会变化。方法区域(Method Area)也是属于非堆区域,也是一种应用程序的元数据。方法区域用于存放应用程序的代码。非堆区域的大小可由参数-XX:MaxPermSize决定。
- 其他区域包含了Java虚拟机自身使用的数据,代码,JIT编译器生成的机器代码,和一些缓存数据等。
我们下面将会详解介绍堆区域的内存管理,因为堆区域的内存管理是与垃圾回收器紧密相连的。它的管理方式直接影响着应用程序运行的效率。我们将在下一章详细介绍Java虚拟机的垃圾回收机制。
3 堆区域内存管理
Java虚拟机将堆区域分为两个子区域:新生代区域(Nursery或者Young Generation Area)和老年代区域(Old Generation Area)。这样的划分方法是为了优化Java垃圾回收机制而制定的。众所周知,Java不需要开发人员释放使用完毕的对象,对象回收是由垃圾回收器自动完成的。当垃圾回收器运行时,它会扫描部分或者全部的对象,并释放那些未被引用的对象。当垃圾回收器运行时,Java虚拟机会暂定Java程序的运行。因此,垃圾回收器运行的速度将直接影响Java程序的运行。
为了优化Java垃圾回收过程,Java的开发者们对Java程序进行了长年累月的分析与研究。他们发现绝大部分的Java对象可被分为两类。一类是“瞬时”对象,即对象刚被创建不久,经短时间运行之后就可以被释放了。另一类是“持久型”对象,即对象被创建后,会长时间的处于使用状态。根据这个观察结果,Java虚拟机采用了以存活时间长短为依据来区分和管理对象的方式。
如图一所示,新生代区域存放新创建的对象。新生代区域包括Eden区域、S0和S1区域。所有新创建的对象会被放入Eden区。经过一段时间后,仍然存活的对象会被移入S0或者S1区。S0和S1是对等的、相同功能的区域。其用处是,如果目前所有对象都在S0区的话,经垃圾回收器扫面后,所有存活的对象会被移入S1区。此时S0区被清空。然后,当下一轮扫面过后,所有存活的对象会从S1区移入S0区;S1区被清空。如此往复。当对象的存活时间超过一个阈值(Threshold)时,会被移入老年代区(Old Generation Area)。这种实现方法是下一章将要介绍的Sweep-and-Copying策略。
Java虚拟机会对新生代区域和老年代区域分别应用不同的垃圾回收策略。我们将在下一章详细介绍。
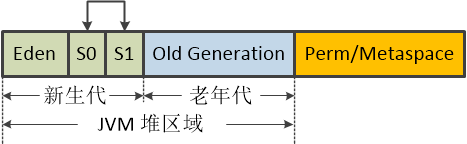
图一 Java虚拟机堆区域内存布局。
4 Java的堆与栈
在介绍完堆区域之后,我们再来比较一下Java虚拟机使用的堆和栈。堆和栈是程序设计中常被提及的两个概念。一般的,堆用于分配动态内存,而栈用于保存函数调用的状态。但是,在Java虚拟机中,情况略复杂一些。
Java虚拟机本身是一个程序,因此,它本身是依赖于堆和栈运行的。与此同时,Java虚拟机解释运行Java的程序。为了运行Java程序,Java虚拟机还为其准备了堆和栈。这个堆就是我们上述的堆空间,而栈则保存了Java程序函数调用的状态。
准确的说,Java程序的堆和栈并不是对等的两个概念。每个Java虚拟机只为Java程序准备一个堆区域;然而,Java虚拟机会为每个Java程序的线程创建一个调用栈。因此,一个Java程序只有一个堆,但是可能有多个栈。
图二显示的是下面程序运行于第8行的调用栈状态和堆内存布局。程序开始于main()函数,然后调用init()方法,最后调用createInteger()方法,停在了第8行。因此,在图二中,最左侧的方框自下而上地显示了函数调用的顺序。然而,在Java虚拟机中,方法调用的顺序是保存在调用栈上的。在栈上,每个函数使用的区域被称为一个Frame,所以,根据Frame的顺序就能推出函数调用的顺序。而且,在每个Frame中,还保存了方法定义的临时变量。基本数据类型的临时变量和对象引用都存放在栈中。例如:createInteger()方法定义的临时变量i和j,和main()函数定义的对象引用example。而在程序运行的过程中,动态创建出来的(使用关键字new创建出来的)对象则存放在堆区域中。所以,CallStackExample()对象是存放在堆区域的。这个规则有一个例外,因为Java虚拟机对String对象做了特殊处理,所以,所有在程序中定义的String对象都是存放在常量池中的。因为从命令行输入的参数是一个字符串数组,所有的数组都是存放在堆区域的。
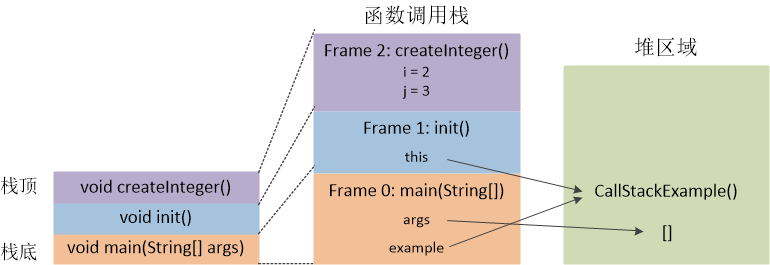
图二 Java虚拟机的堆和栈。
public class CallStackExample {
private Integer pid = null;
public void init() {
this.pid = createInteger();
}
public Integer createInteger() {
int i = 2;
int j = 3;
return Integer.of(i * j); // 假设程序运行后,暂停在这一行
}
public static void main(String[] args) {
CallStackExample example = new CallStackExample();
example.init();
}
}
如果读者想进一步了解Java程序中调用栈的工作原理,可查看我们的OnlineTutor在线程序。
5 总结
本章讲解了Java虚拟机中内存的分布、以及比较了Java程序中堆与栈的联系与区别。我们将在下一章介绍与内存管理息息相关的垃圾回收机制。
上一章
下一章
注册用户登陆后可留言