- 一、设计模式介绍(Introduction of Design Pattern)
- 二、工厂模式(Factory Method Pattern)
- 三、抽象工厂模式(Abstract Factory Pattern)
- 四、建造者模式(Builder Pattern)
- 五、原型模式(Prototype Pattern)
- 六、单例模式(Singleton Pattern)
- 七、对象池模式(Object Pool Pattern)
- 八、适配器模式(Adapter Pattern)
- 九、桥接模式(Bridge Pattern)
- 十、组合模式(Composite Pattern)
- 十一、装饰模式(Decorator Pattern)
- 十二、外观模式(Facade Pattern)
- 十三、享元模式(Flyweight Pattern)
- 十四、代理模式(Proxy Pattern)
- 十五、责任链模式(Chain of Responsibility Pattern)
- 十六、命令模式(Command Pattern)
- 十七、解释器模式(Interpreter Pattern)
- 十八、迭代器模式(Iterator Pattern)
- 十九、中介者模式(Mediator Pattern)
- 二十、备忘录模式(Memonto Pattern)
- 二十一、观察者模式(Observer Pattern)
- 二十二、状态模式(State Pattern)
- 二十三、策略模式(Strategy Pattern)
- 二十四、模板模式(Template Pattern)
- 二十五、访问者模式(Visitor Pattern)
- 二十六、空对象模式(Null Object Pattern)
- 二十七、私有类数据模式(Private Class Data Pattern)
- 二十八、发布-订阅模式(Publish-Subscribe Pattern)
- 二十九、控制反转(Inversion of Control)
- 三十、依赖注入模式(Dependency Injection Pattern)
第十三章 享元模式(Flyweight Pattern)
1 概要
享元模式(Flyweight Pattern)是一种结构模式(Structural Design Pattern)。它的设计初衷是为了节省内存开销。在面向对象程序设计中,所有的数据都包含在对象中。在某些场景下,有些数据是高度重复的。当使用这些重复数据时,如果每次都重新创建一个对象的话,那么,这种方式“浪费”了许多内存空间,以及“浪费”了CPU资源来反复的创建和销毁这些对象。
一个更加有效的使用这些重复数据的方式是将其设置为共享数据。这些共享数据有两个显著的特点。其一,共享数据是不会变化的。如果这些数据可能发生变化的话,这些数据是不能共享的。其二,系统中只有一份共享数据。在需要使用这些数据的地方都使用这一份共享的数据。
2 享元模式的结构
在享元模式中有着4个参与方。
- 享元抽象类Flyweight定义了对象共享的属性。
- 具体享元类ConcreteFlyweight实现了享元抽象类的方法。享元模式并没有规定如何共享对象。开发出来的程序只要能共享享元对象,都算是使用了享元模式。因为,享元模式的核心思想是共享对象。
- 享元工厂FlyweightFactory用于创建共享对象。享元工厂是享元模式的核心所在,因为它实现了如何共享对象。
- 客户Client请求创建共享对象和使用共享对象。
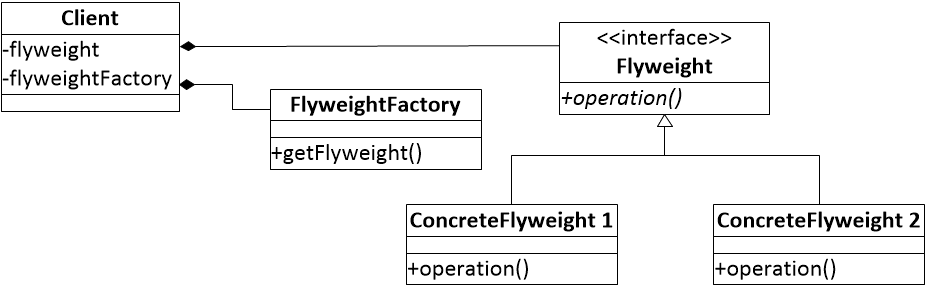
图一 享元模式结构。
3 享元模式示例
我们将以在校本科学生和所完成的课程为例,展示享元模式的使用方法。首先,我们先定义享元抽象类CompletedCourses。该类用于表示一名学生已完成的课程。
import java.util.List;
public abstract class CompletedCourses {
private List<String> completedCourses = null;
public CompletedCourses(List<String> aCourseList) {
this.completedCourses = aCourseList;
}
}
然后,我们定义表示大一至大四学生所完成课程的类。CoursesCompletedByFreshman、CoursesCompletedBySophomore、CoursesCompletedByJunior和CoursesCompletedBySenior分别表示大一、大二、大三和大四学生所完成的课程。
import java.util.List;
import java.util.Collections;
import java.util.Arrays;
public class CoursesCompletedByFreshman extends CompletedCourses {
public CoursesCompletedByFreshman() {
// 大一新生还没有完成任何课程
super(Collections.EMPTY_LIST);
}
}
public class CoursesCompletedBySophomore extends CompletedCourses {
public CoursesCompletedBySophomore() {
// 假设大二学生已完成大一课程"Introduction to Computer Science"
super(Arrays.asList("Introduction to Computer Science"));
}
}
public class CoursesCompletedByJunior extends CompletedCourses {
public CoursesCompletedByJunior() {
// 假设大三学生已完成大一课程和大二课程
super(Arrays.asList("Introduction to Computer Science", "Data Structures"));
}
}
public class CoursesCompletedBySenior extends CompletedCourses {
// 假设大三学生已完成大一课程、大二课程和大三课程
public CoursesCompletedBySenior() {
super(Arrays.asList(
"Introduction to Computer Science",
"Data Structures",
"Operating Systems"));
}
}
然后,我们使用类Student来表示一名在校本科生。其中,成员变量用于表示该学生已完成的课程列表。我们在main()函数中创建了三名大一学生Adam, David和Amy,和一名大二学生Julie。
public class Student {
private String name = null;
private CompletedCourses courses = null;
public Student(String name, CompletedCourses courses) {
this.name = name;
this.courses = courses;
}
public static void main(String[] args) {
CompletedCourseFactory factory = new CompletedCourseFactory();
// 创建大一学生Adam
Student adam = new Student("Adam", factory.make("freshman"));
// 创建大一学生David
Student david = new Student("David", factory.make("freshman"));
// 创建大一学生Amy
Student amy = new Student("Amy", factory.make("freshman"));
// 创建大二学生Julie
Student julie = new Student("Julie", factory.make("sophomore"));
}
}
最后,我们再来看看如何实现CompletedCourseFactory工厂类。该工厂类定义了一个静态成员变量sharedCompletedCourses用于存放共享的对象。每当需要创建一个新对象时,该工厂类会首先在共享池中查找是否已存在。如果已存在,则直接返回该共享对象。如果不存在,则创建一个新对象,并将其添加到共享池中。因此,在整个应用程序中,我们只会创建出四个对象,分别表示大一至大四各阶段所完成的课程列表。
import java.util.Map;
import java.util.HashMap;
public class CompletedCourseFactory {
private static Map<String, CompletedCourses> sharedCompletedCourses = new HashMap<>();
public CompletedCourses make(String year) {
CompletedCourses courseList = sharedCompletedCourses.get(year);
if (courseList != null) {
// 如果已存在共享池中,则直接返回该共享对象。
return courseList;
}
// 否则创建一个新对象
switch (year) {
"freshman":
courseList = new CoursesCompletedByFreshman();
break;
"sophomore":
courseList = new CoursesCompletedBySophomore();
break;
"junior":
courseList = new CoursesCompletedByJunior();
break;
"senior":
courseList = new CourseCompletedBySenior();
break;
default:
// should not reach here
throw new IllegalArgumentException("Unsupported year.");
}
sharedCompletedCourses.add(year, courseList);
return courseList;
}
}
4 应用举例
Java标准库中也使用了享元模式。在Integer类中缓存了常用的Integer对象。从下面的实现来看,Integer类中实现了一个内部类IntegerCache,用于表示缓存的Integer对象。IntegerCache类中成员变量low和high指出了缓存整数数值的范围;cache则是这些缓存整数的数组。
当Integer.valueOf()函数被调用时,如果传入参数的值在缓存数据的数值范围内时,会返回已缓存的Integer对象。
// OpenJDK 15
package java.lang;
public final class Integer extends Number implements Comparable<Integer> {
...
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
}
...
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
...
}
在Java虚拟机的实现中,也使用了对象共享的思想,只不过它们的实现方式可能不同。例如,class对象是一种共享对象。当程序创建出两个不同的对象,并获取它们的class对象时,实际上,它们的class对象是同一个共享对象。这样做的原因是为了避免生成过多的重复对象,其思想与享元模式相同。
public class SharedObjectExample {
public static void main(String[] args) {
SharedObjectExample obj1 = new SharedObjectExample();
SharedObjectExample obj2 = new SharedObjectExample();
// 使用 == 操作符比较它们是否指向同一个对象
if (obj1.getClass() == obj2.getClass()) {
System.out.println("They share the class object.");
}
}
}
5 小结
本章介绍了享元模式的结构和使用方法。享元模式的主要出发点是共享对象,以解决内存使用过多的问题。享元模式适用于当应用程序需要创建大量的对象,并且这些对象有着大量重复数据的场景。此时,可以将重复的数据抽象为一个共享的类。享元模式还可以和其他模式配合使用,使代码更高效。
上一章
下一章
注册用户登陆后可留言