栈与队列 (Stacks and Queues)
1. 栈(Stacks)
栈(stacks)是一个先进后出(First-In-First-Out),后进先出的数据结构,可以使用数组或者链表实现。所以一个栈中元素的数据类型也必须是相同的。栈的操作主要有入栈(push)和出栈(pop)。入栈(push)操作将一个新元素存入栈,出栈(pop)操作返回栈顶元素并将其从栈中删除。因为出栈和入栈操作都发生在栈顶,所以需要一个指向栈顶元素的名为top的引用。
我们可以把栈想象为只允许从最上方放入(入栈)或者取走(出栈)的一摞书,元素想象为书。放入(入栈push)时将书放在最上面(top),取书(出栈pop)时将书从最上方取走。所以出栈和入栈都只能发生在栈顶,最先进入栈的元素最后离开,最后进入栈的元素最先离开。
关于null引用,我们在本章的示意图中使用了null,也就是Java中的关键字,虽然不完全一样,但在此处它相当于C++中的Null和Python中的None。

- 用数组实现栈
因为数组的大小是固定的,所以如果使用数组实现栈,必须在初始化栈的时候设定栈的最大长度,也就是数组大小。栈的大小必须小于所在数组的大小。用这种方式实现的栈内存使用效率不及用链表。但是当栈的大小小于数组大小的时候,因为数组的整个内存已经在初始化的时候分配好了,入栈(push)操作不会因为内存不足而失败。
以下是一个用Java数组实现的栈。
查看和下载源代码public class ArrayStack <E> {
// 因为是用数组实现的,数组的大小就是栈大小的上限,默认设为10。
private int maxSize = 10;
// vals数组用来实现堆栈。
private Object vals[];
// 栈顶的索引值,当top为-1时该栈为空。
private int top = -1;
// 可以设定数组大小的构造函数。
public ArrayStack(int size) {
maxSize = size;
vals = new Object[maxSize];
}
// 使用默认值设定数组大小的构造函数。
public ArrayStack() {
vals = new Object[maxSize];
}
// pop操作。
public E pop() {
if(top>=0) {
E result = (E)vals[top];
// vals[top]=null;
top--;
return result;
} else {
throw new IllegalArgumentException("Stack is empty, cannot pop.");
}
}
// push操作。
public void push(E item) {
if (top >= maxSize-1) {
throw new IllegalArgumentException("Stack is full, cannot push more items.");
} else {
top++;
vals[top] = item;
}
return;
}
public boolean isEmpty() {
if (maxSize == 0) {
return true;
} else {
return true;
}
}
}
-
入栈(push)操作
以下是入栈(push)操作的代码。因为数组实现的栈受限于数组的初始化大小,所以先检查top是不是等于maxSize-1。如果是,则数组已满,不能再添加新元素。否则,当栈未满时,栈顶索引增加1,将元素存于栈顶处。
public void push(E item) {
if (top >= maxSize-1) {
throw new IllegalArgumentException("Stack is full, cannot push more items.");
} else {
top++;
vals[top] = item;
}
return;
}
-
出栈(pop)操作
以下是出栈(pop)操作的代码。如果当前栈为空,则不能出栈。如果不为空,即top>=0,则返回栈顶元素,栈顶索引top减1。
注意有一行注释掉的代码。它将出栈元素在数组内重置为null,我们是否需要这行代码呢?
如果栈操作严格遵守栈的规则,我们不需要将该元素在数组中重置。因为对于栈来讲,在栈顶以外的所有元素都不是有效数据。当栈顶索引top减1之后,原栈顶元素已经在现在的栈顶之外了。
public E pop() {
if(top>=0) {
E result = (E)vals[top];
// vals[top]=null; // 将出栈元素在数组内重置为null。
top--;
return result;
} else {
throw new IllegalArgumentException("Stack is empy, cannot pop.");
}
}
如果我们按顺序运行如下的语句,该栈所在数组的变化如图所示。
ArrayStack nameStack = new ArrayStack();
nameStack.push("Adam");
nameStack.push("Bob");
nameStack.push("Chris");
nameStack.push("David");
System.out.println(nameStack.pop());
System.out.println(nameStack.pop());
System.out.println(nameStack.pop());
System.out.println(nameStack.pop());
ArrayStack nameStack = new ArrayStack();

nameStack.push("Adam");
Adam存在索引0,栈顶(top)更新为0。

nameStack.push("Bob");
Bob存在索引1,栈顶(top)更新为1。

nameStack.push("Chris");
Chris存在索引2,栈顶(top)更新为2。

nameStack.push("David");
David存在索引3,栈顶(top)更新为3。

System.out.println(nameStack.pop());
在这一步之前时(上图),栈顶top值为3,所以栈顶元素是David。需要注意的是这一步出栈操作pop返回了栈顶值David,同时将top减1。如果我们看下图表示的本语句之后的状态,top=2,但David仍在数组内。但是因为David的索引为3,在栈顶之外,所以对于栈来说David不是有效数据。栈顶(top)更新为2。

System.out.println(nameStack.pop());
栈顶(top)更新为1。

System.out.println(nameStack.pop());
栈顶(top)更新为0。

System.out.println(nameStack.pop());
栈顶(top)更新为-1,当前堆栈为空。

- 用链表实现栈
链表的长度是可以动态变化的,每入栈(push)一个元素,都会分配相应的内存,所以用链表实现栈可以有效地利用内存。因为栈的特性,当用链表实现栈时,入栈(push)和出栈(pop)操作都发生在链表头,且只入栈或出栈一个元素。所以所有的入栈和出栈操作均可在固定的时间内完成。
以下是一个用单链表结构实现的栈类。
查看和下载源代码public class LinkedListStack <E> {
// 链表的节点。
private class Node {
public E element;
public Node next;
public Node(E element, Node next) {
this.element = element;
this.next = next;
}
public String toString() {
return element.toString();
}
}
// 在用链表实现的堆栈中,可将表头引用替换为栈顶引用top。
private Node top;
private int size;
public LinkedListStack() {
top = null;
size = 0;
}
public int getSize() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
// 入栈操作,其实本质上就是单链表例子中的addFirst函数。
public void push(E element) {
top = new Node(element, top);
size++;
}
// 出栈操作,返回栈顶元素值,更新栈顶引用到原栈顶元素之后的节点,并移除栈顶节点。
public E pop() {
if (size == 0)
return null;
E result = top.element;
top = top.next;
size--;
return result;
}
}
- 入栈(push)操作
创建一个包含元素值的新节点,并将其插入在栈顶(实际上就是链表表头)。并将栈顶引用更新为新插入的节点。这个操作本质上就是我们之前单链表内的addFirst函数。
public void push(E element) {
top = new Node(element, top);
size++;
}
- 出栈(pop)操作
返回栈顶节点的元素值并将栈顶指向其下一个节点。因为Java的垃圾回收机制(Garbage Collection)会自动释放没有被引用的对象(object)。这个操作事实上的作用包括了删除原栈顶节点。
public E pop() {
if (size == 0)
return null;
E result = top.element;
top = top.next;
size--;
return result;
}
如果我们按顺序运行如下的语句,该栈所在链表的变化如图所示。
LinkedListStack nameStack = new LinkedListStack();
nameStack.push("Adam");
nameStack.push("Bob");
nameStack.push("Chris");
nameStack.push("David");
System.out.println(nameStack.pop());
System.out.println(nameStack.pop());
System.out.println(nameStack.pop());
System.out.println(nameStack.pop());
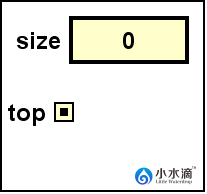
LinkedListStack nameStack = new LinkedListStack();
栈初始化为空栈,top引用为null,size为0。
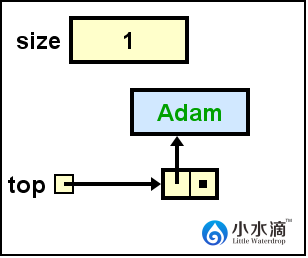
nameStack.push("Adam");
将“Adam”入栈,入栈操作必须在栈顶。更新top为指向Adam节点的引用。
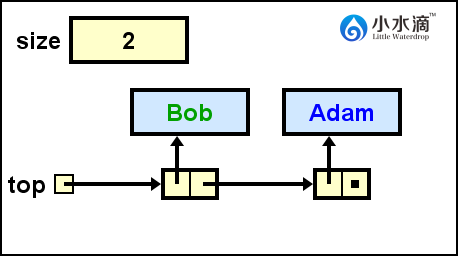
nameStack.push("Bob");
将“Bob”入栈,将栈顶top更新为指向Bob节点的引用。
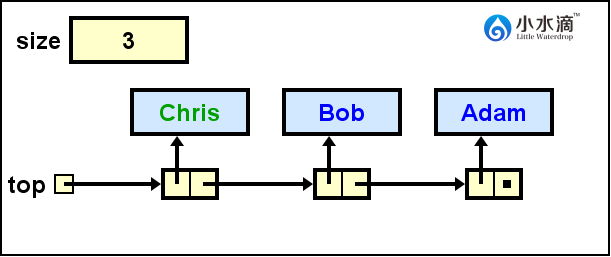
nameStack.push("Chris");
将“Chris”入栈,将栈顶top更新为指向Chris节点的引用。
nameStack.push("David");
将“David”入栈,将栈顶top更新为指向David节点的引用。
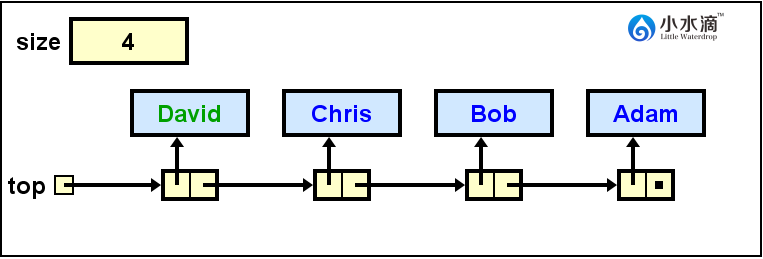
System.out.println(nameStack.pop());
因为出栈操作也必须在栈顶发生,所以出栈操作总是返回和移除栈顶元素,也不必给出位置和元素值。在本操作前,栈的状态为上图,即David在栈顶,所以我们需要返回David的值,然后在栈顶移除它,并更新栈顶为指向下一节点Chris的引用。
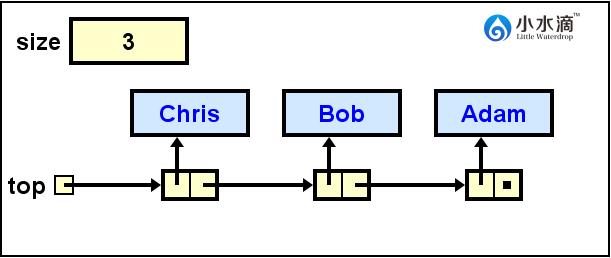
System.out.println(nameStack.pop());
返回Chris的值,然后在栈顶移除它,并更新栈顶为指向下一节点Bob的引用。
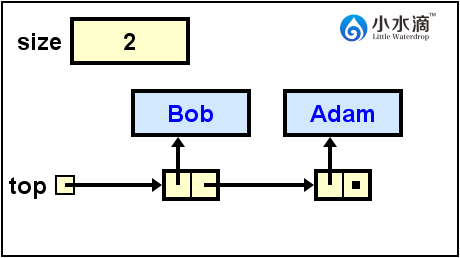
System.out.println(nameStack.pop());
返回Bob的值,然后在栈顶移除它,并更新栈顶为指向下一节点Adam的引用。
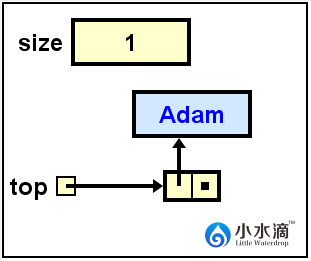
System.out.println(nameStack.pop());
返回Adam的值,然后在栈顶移除它,并更新栈顶为指向下一节点的引用,因为Adam是该栈中最后一个节点,移除后栈顶更新为null。
2. 队列(Queues)
队列是一个先进先出(First-In-First-Out)的数据结构。队列的主要操作有入队(enqueue)和离队(dequeue)。其中入队(enqueue)只能发生在队尾,而离队只能发生在队头。比如下图中如果有一群人在排队,队头(head)的人可以出队(dequeue),入队(enqueue)的人必须排在队尾(tail)。

- 链表队列
以下是一个用Java单链表实现的队列 。需要注意的是在该队列中,除了通常单链表结构都有的指向链表开始位置(表头)的引用head,还有一个引用tail指向该链表的最后一个节点。这样做是因为队列的入队(Enqueue)操作总是发生在队尾(表尾)。为了避免遍历整个单链表结构来找到表尾,我们可以通过tail直接访问表尾来进行入队操作。
查看和下载源代码public class LinkedListQueue <E> {
private class Node {
public E element;
public Node next;
public Node(E element, Node next) {
this.element = element;
this.next = next;
}
public String toString() {
return element.toString();
}
}
private Node head;
private Node tail;
private int size;
public LinkedListQueue() {
head = null;
tail = null;
size = 0;
}
public int getSize() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
public void enqueue(E element) {
Node n = new Node(element, null);
if(tail == null) {
head = n;
tail = n;
} else {
tail.next = n;
}
tail = n;
size++;
}
public E dequeue() {
if (head == null)
return null;
E result = head.element;
head = head.next;
size--;
return result;
}
}
-
入队(Enqueue)
以下是入队(Enqueue)操作的代码。在队列中,新入队的元素的节点必须插入到队列的末尾。队列可以通过tail来直接访问表尾,所以不需要像在单链表中从表头遍历来查找表尾。
public void enqueue(E element) {
Node n = new Node(element, null);
if(tail == null) {
head = n;
tail = n;
} else {
tail.next = n;
}
tail = n;
size++;
}
-
出队(Dequeue)
以下是出队(dequeue)操作的代码。队列仅能出队(dequeue)队首的节点。所以出队总是发生在表头。出队操作仅需要将head更新为指向下一个节点的引用即可。
public E dequeue() {
if (head == null)
return null;
E result = head.element;
head = head.next;
size--;
return result;
}
如果我们按顺序运行如下的语句,该栈所在数组的变化如图所示
LinkedListQueue nameQueue = new LinkedListQueue();
nameQueue.enqueue("Adam");
nameQueue.enqueue("Bob");
nameQueue.enqueue("Chris");
nameQueue.enqueue("David");
System.out.println(nameQueue.dequeue());
System.out.println(nameQueue.dequeue());
System.out.println(nameQueue.dequeue());
System.out.println(nameQueue.dequeue());
LinkedListQueue nameQueue = new LinkedListQueue();
队列初始化为空队列,队头的head引用为null,队尾tail引用为null,size为0。
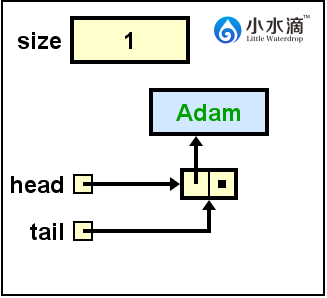
nameQueue.enqueue("Adam");
将“Adam”入队(enqueue),入队操作必须在队尾(tail)。但是因为当前队列为空,所以将head和tail都更新为指向Adam节点的引用。
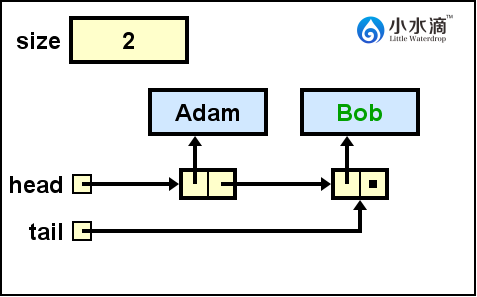
nameQueue.enqueue("Bob");
将“Bob”入队。因为入队操作必须在队尾,将队尾tail更新为指向Bob节点的引用。
nameQueue.enqueue("Chris");
将“Chris”入队。因为入队操作必须在队尾,将队尾tail更新为指向Chris节点的引用。
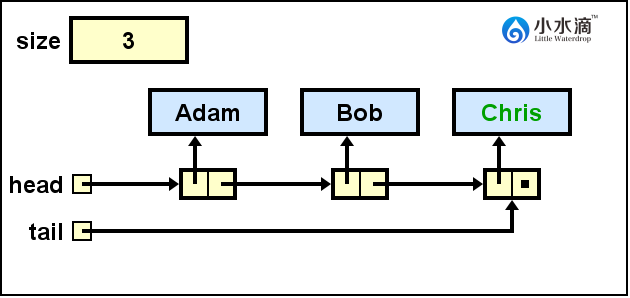
nameQueue.enqueue("David");
将“David”入队。因为入队操作必须在队尾,将队尾tail更新为指向David节点的引用。
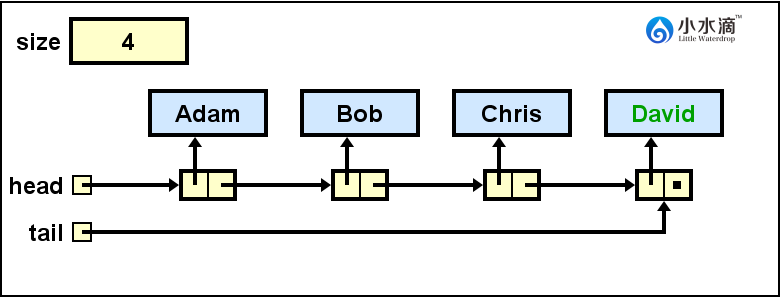
System.out.println(nameQueue.dequeue());
因为出队(dequeue)操作必须在队头(head)发生,所以出队操作总是返回和移除队头元素,也不必给出位置和元素值。本操作在前,队列的状态为上图,即Adam在队头。所以我们需要返回Adam的值,然后在队头移除它,并更新队头head为指向下一节点Bob的引用。
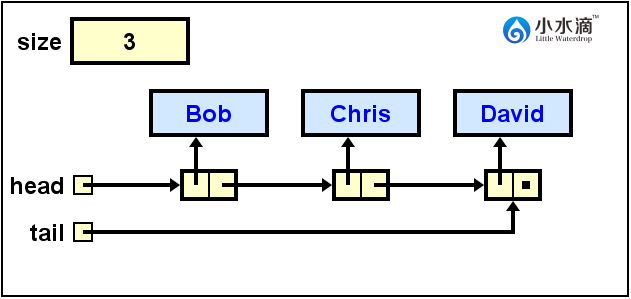
System.out.println(nameQueue.dequeue());
返回Bob的值,然后在队头移除它,并更新队头为指向下一节点Chris的引用。
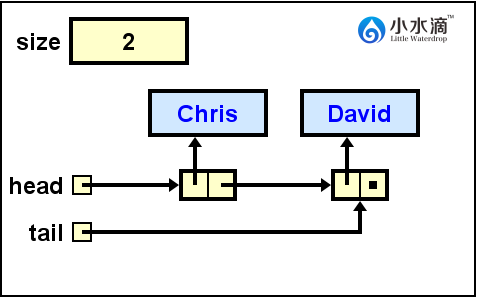
System.out.println(nameQueue.dequeue());
返回Chris的值,然后在队头移除它,并更新队头为指向下一节点David的引用。
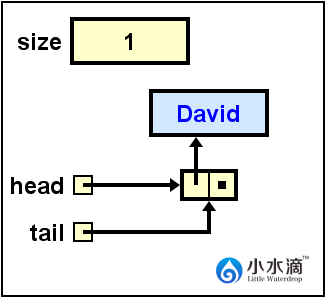
System.out.println(nameQueue.dequeue());
返回David的值,然后在队头移除它,并更新队头为指向下一节点的引用,因为David是该队列中最后一个节点,移除后队头和队尾都更新为null。
- 循环数组队列
队列也可以用数组实现。但是由于数组的大小是固定不变的,所以队列长度的上限受限于数组的长度。为了更有效的利用有限的数组空间,通常使用循环数组来实现队列。
以下是一个用Java数组实现的队列 。需要注意的是在该队列中,我们有两个数组索引front和rear来表示指向队列在数组中的起始位置(front,即队头)和结束位置(rear,即队尾)。这样做是因为队列的入队(Enqueue)操作总是发生在队尾(表尾),我们可以通过对应的数组索引位置直接找到队头和队尾。为了有效的利用数组空间,队列可以循环地利用数组空间。比如当enqueue操作时,如果rear在数组的最后一个元素上,且front索引之前还有空位置,新入队的元素则会添加到数组的开始部分。
查看和下载源代码public class CircularArrayQueue <E> {
private int maxSize = 10;
private Object vals[];
private int length = 0;
private int front = 0;
private int rear = -1;
public CircularArrayQueue(int size) {
maxSize = size;
vals = new Object[maxSize];
}
public CircularArrayQueue() {
vals = new Object[maxSize];
}
public void enqueue(E item) {
if(isFull()) {
throw new IllegalArgumentException("Queue is full, cannot enqueue more items.");
} else {
rear = (rear+1) % maxSize;
vals[rear] = item;
length++;
}
}
public E dequeue() {
if(isEmpty()) {
throw new IllegalArgumentException("Queue is empty, cannot dequeue.");
} else {
E result = (E)vals[front];
front = (front+1) % maxSize;
length--;
return result;
}
}
public boolean isEmpty() {
if(length == 0)
return true;
else
return false;
}
public boolean isFull() {
if(length == maxSize)
return true;
else
return false;
}
}
-
入队(Enqueue)
以下是入队(Enqueue)操作的代码。在队列中,新入队的元素的节点必须插入到队列的末尾。因为我们需要循环利用数组空间,所以更新rear的时候用到了取余运算。
public void enqueue(E item) {
if(isFull()) {
throw new IllegalArgumentException("Queue is full, cannot enqueue more items.");
} else {
rear = (rear+1) % maxSize;
vals[rear] = item;
length++;
}
}
-
出队(Dequeue)
以下是出队(dequeue)操作的代码。队列仅能出队(dequeue)队首的节点。所以出队总是发生在队头(front)。在获取出队元素的值后,我们仅需要将front增加1,然后取除以maxSize的余数,即为新的front。取余运算的目的同为循环利用数组空间。
public E dequeue() {
if(isEmpty()) {
throw new IllegalArgumentException("Queue is empty, cannot dequeue.");
} else {
E result = (E)vals[front];
front = (front+1) % maxSize;
length--;
return result;
}
}
如果我们按顺序运行如下的语句,该栈所在数组的变化如图所示
CircularArrayQueue nameQueue = new CircularArrayQueue(5);
nameQueue.enqueue("Adam");
nameQueue.enqueue("Bob");
nameQueue.enqueue("Chris");
nameQueue.enqueue("David");
nameQueue.enqueue("Eric");
System.out.println(nameQueue.dequeue());
System.out.println(nameQueue.dequeue());
nameQueue.enqueue("Frank");
nameQueue.enqueue("Gary");
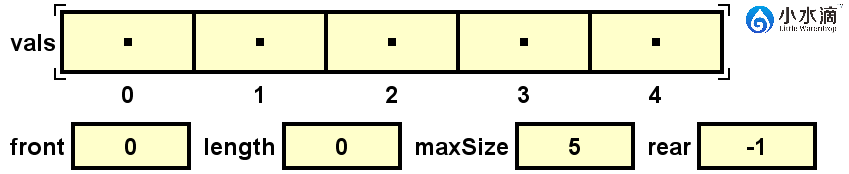
CircularArrayQueue nameQueue = new CircularArrayQueue(5);
队列初始化为空队列,数组长度为5,队头的front索引为1,队尾rear的索引为-1,队列长度length为0。
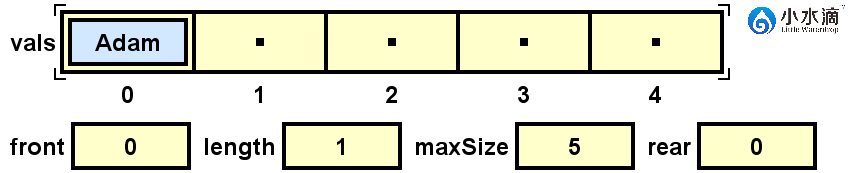
nameQueue.enqueue("Adam");
将元素Adam入队在(rear+1)% maxSize的索引上。rear为操作前队尾所在位置,maxSize是队列所在数组的长度,也就是队列能达到的最大长度,当前为5。因为之前队尾为空,rear值为-1,(rear+1)% maxSize结果为0。取余运算是为了循环利用数组。
nameQueue.enqueue("Bob");
nameQueue.enqueue("Chris");
nameQueue.enqueue("David");
nameQueue.enqueue("Eric");
同理我们将“Bob”,“Chris”,“David”,“Eric”依次入队得到下图结果。当前队列已经达到最大长度不能再入队。
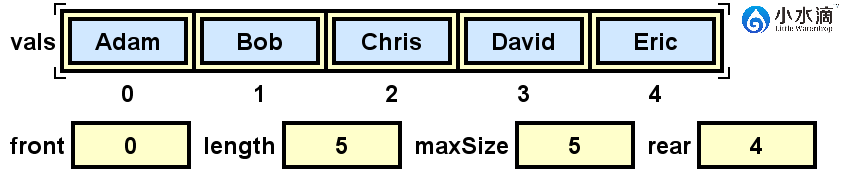
System.out.println(nameQueue.dequeue());
如果我们此时运行出队操作,当前(上图)队列队头的元素“Adam”将会出队,此时队头索引front将会更新为(front+1)% maxSize(此结果为1)。
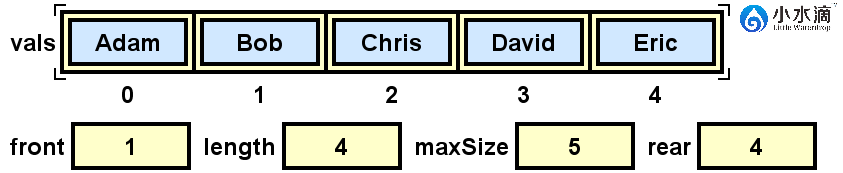
System.out.println(nameQueue.dequeue());
如果我们此时再运行一个出队操作,当前(上图)队列队头的元素“Bob”将会出队,此时队头索引front将会更新为(front+1)% maxSize(此结果为2)。
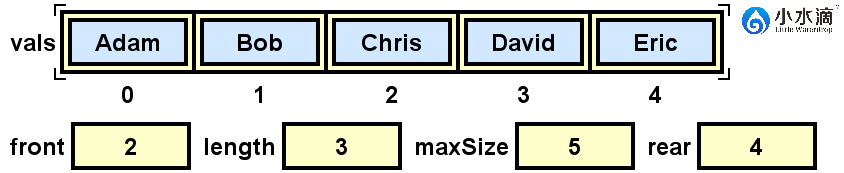
nameQueue.enqueue("Frank");
如果我们此时再入队元素“Frank”,会发现虽然此时(上图)队列不满,rear索引已经是当前数组最大的索引值4。此时计算(rear+1)% maxSize,可以得到结果为0。所以“Frank”会被插入在索引为0的位置。
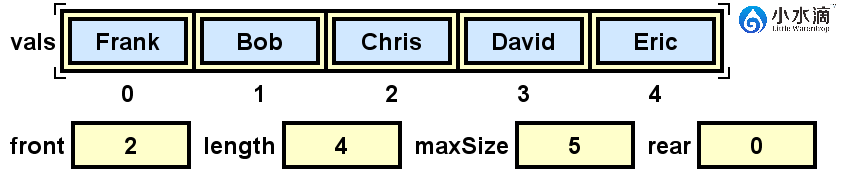
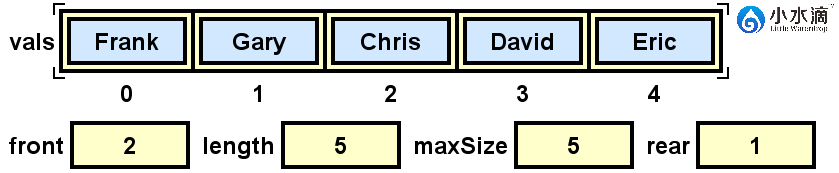
nameQueue.enqueue("Gary");
如果我们此时再入队元素“Gary”,rear为0,计算(rear+1)% maxSize,可以得到结果为1。所以“Gary”会被插入在索引为1的位置。
上一章
下一章
注册用户登陆后可留言