链表 (Linked Lists)
1. 单向链表(Singly Linked Lists)
单向链表包含一系列的节点。这些节点可以是在内存中不相邻的。每个节点都包含该节点的元素(element)和指向下一个节点的引用(next)。一个链表中所有节点(node)的元素(element)必须是同一种数据类型。最后一个节点的next为空(null)。所以只要能够访问第一个节点,就能顺藤摸瓜地遍历整个链表。但是单向链表只能从头到尾单向遍历,也就是说当得到一个节点的引用后,可以获得下一个节点的引用却无法获得上一个节点的引用。
不同于C++使用指针来指向一个节点,Java使用引用(reference)指向节点。
单向链表的抽象数据类型(Abstract Data Types, or ADT)至少有以下几个基本操作:add, remove...
- 单向链表的插入操作
单向链表的插入操作按插入位置分为三种情况,从表头插入,从表尾插入,和从中间插入。在每次插入操作前需要判断链表是否为空以避免发生NullPointerException异常。在一个单向链表中有一个引用head指向该表的头节点,如果插入的节点会变成新的头节点,head的值需要更新为新插入节点的引用(reference)。单向链表的插入操作会增加链表长度,并影响插入的节点之前位置节点的next值。下面我们用几个例子来解释。
下面的类LinkedList仅包含了上述的插入和删除操作。
查看和下载源代码// 单向链表类LinkedList。
public class LinkedList < E > {
// 节点类Node,包括两个属性:元素element(泛型)和指向下一个节点的引用next。
private class Node {
public E element; // 泛型元素element。
public Node next; // 指向下一节点的引用next。
// 节点的构造函数。
public Node(E element, Node next) {
this.element = element;
this.next = next;
}
}
// LinkedList类的两个属性。
// 链表为空时head值为null。链表非空时head总是指向头节点。
// size存有当前链表的节点个数。
private Node head;
private int size;
// 链表类的构造函数。
public LinkedList() {
head = null;
size = 0;
}
// 返回当前节点个数。
public int getSize() {
return size;
}
// 查看当前链表是否为空。
public boolean isEmpty() {
return size == 0; // 也可以通过检查next是否为null来判断链表是否为空。
}
// 在指定索引(index)处添加一个元素为element的节点。
public void add(E element, int index) {
// index值必须大于等于0且小于等于size,否则抛出IllegalArgumentException异常。
if (index < 0 || index > size)
throw new IllegalArgumentException("Index out of range.");
// 如果index为0则插入位置在表头。需要创建一个Node节点并将其元素初始化为element,next初始化为之前的表头head。
// 最后将表头head更新为插入节点的引用。
if (index == 0) {
head = new Node(element, head);
} else {
// 否则index是正整数,则插入在表中或者表尾。
// 遍历到插入位置的前一个节点current,将current的next(原本的下一个节点)赋值给插入节点的引用next,
// 再将current的next更新为插入节点的引用。
Node current = head;
for (int i = 0; i < index-1; i++) {
current = current.next;
}
current.next = new Node(element, current.next);
}
size++;
}
// 在表头插入元素值为element的节点,需要更新head。
public void addFirst(E element) {
head = new Node(element, head);
size++;
}
// 在表尾插入元素值为element的节点。
public void addLast(E element) {
Node current = head;
if(current == null) {
head = new Node(element, head);
} else {
while (current.next != null) {
current = current.next;
}
current.next = new Node(element, null);
}
size++;
}
public void remove(int index) {
if (index < 0 || index >= size)
throw new IllegalArgumentException("Index out of range.");
Node current = head;
Node prev = null;
if(index == 0) {
head = current.next;
} else {
for(int i = 0;i<index;i++) {
prev = current;
current = current.next;
}
prev.next = current.next;
}
size--;
}
}
如果我们按顺序运行如下的语句。
LinkedList nameList = new LinkedList<String>();
nameList.addFirst("Adam");
nameList.addLast("Bob");
nameList.addFirst("Chris");
nameList.add("David", 1);
每个语句的结果分别如下。
// 新建一个空的字符串(String)单向链表,将size初始化为0,head初始化为null。该链表所有节点的元素(element)只能是String类型。
LinkedList nameList = new LinkedList<String>();
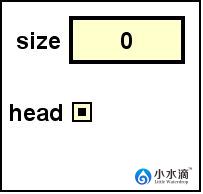
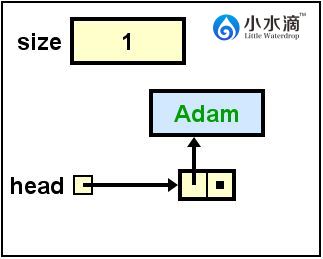
// 将字符串“Adam”插入表头。
nameList.addFirst("Adam");
为了表述清晰,此处附上了addFirst函数的代码。
public void addFirst(E element) {
head = new Node(element, head);
size++;
}
本操作建立了一个元素值(element)为字符串“Adam”的节点,并将此节点插入在单向链表nameList的表头。当前nameList没有节点。
操作描述:
- 创建一个新的节点(node)。
- 将新节点的element属性初始化为字符串“Adam”。
- 将新节点的next属性初始化为当前单向链表的head的值。注意当链表为空时,head = null,所以新插入的节点的next也为null,因为新节点是该链表中唯一的节点。
- 将单向链表的head值更新为新插入节点的引用。
此操作结果如下图所示。
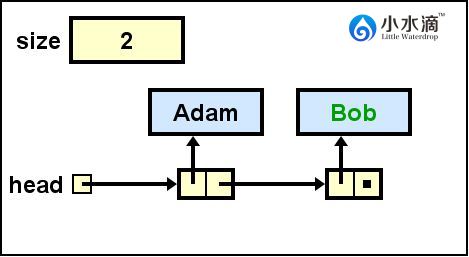
// 将字符串“Bob”插入在表尾。
nameList.addLast("Bob");
为了表述清晰,此处附上了addLast函数的代码。
public void addLast(E element) {
Node current = head;
if(current == null) {
head = new Node(element, head);
} else {
while (current.next != null) {
current = current.next;
}
current.next = new Node(element, null);
}
size++;
}
本操作建立了一个元素值(element)为字符串“Bob”的节点,并将此节点插入在单向链表nameList的表尾。当前nameList有一个节点“Adam”。
操作描述:
- 将新节点的element属性初始化为字符串null。
- 将新节点的next属性初始化为null。
- 如果当前链表为空,则按照addFirst的方法插入。
- 否则因为nameList链表的head属性只指向头节点,需要从头节点顺藤摸瓜找到next是null的节点(即尾节点)。
- 创建一个元素element值为“Bob”的新节点(node),将当前尾节点的next更新为指向该新节点。
此操作结果如下图所示。
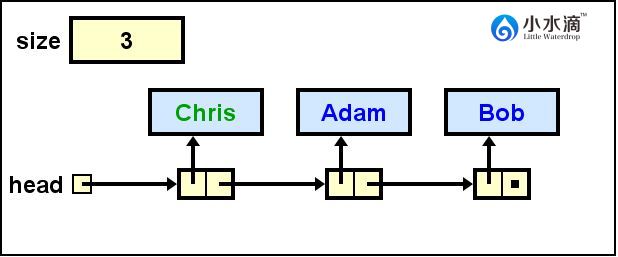
// 将字符串“Chirs插入在当前链表头”
nameList.addFirst("Chris");
本addFirst操作和将字符串“Adam”插入表头的代码相同。区别在于此次运行过程中head不再是null,而是指向元素值为“Adam”节点的引用。
此操作结果如下图所示。
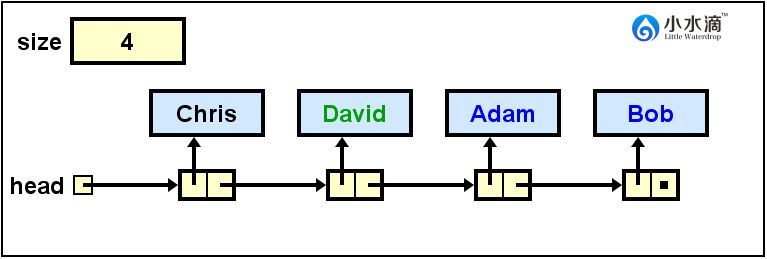
// 将字符串“David”插入在索引index为1的位置(索引从0开始)。
nameList.add("David", 1);
为了表述清晰,此处附上了add函数的代码。
public void add(E element, int index) {
// index值必须大于等于0且小于等于size,否则抛出IllegalArgumentException异常
if (index < 0 || index > size)
throw new IllegalArgumentException("Index out of range.");
// 如果index为0则插入位置在表头。需要创建一个Node节点并将其元素初始化为element,
// next初始化为之前的表头head。最后将表头head更新为插入节点的引用。
if (index == 0) {
head = new Node(element, head);
} else {
// 否则index是正整数,则插入在表中或者表尾。
// 遍历到插入位置的前一个节点current,将current的next(原本的下一个节点)赋值给插入节点的引用next,
// 再将current的next更新为插入节点的引用。
Node current = head;
for (int i = 0; i < index-1; i++) {
current = current.next;
}
current.next = new Node(element, current.next);
}
size++;
}
此操作结果如下图所示。
- 单向链表的删除操作
此remove操作删除处于索引index处的节点。删除后为了保证链表的结构,需要将删除节点的前后链表段再度衔接起来。当删除节点是头节点的时候,注意更新head的值。
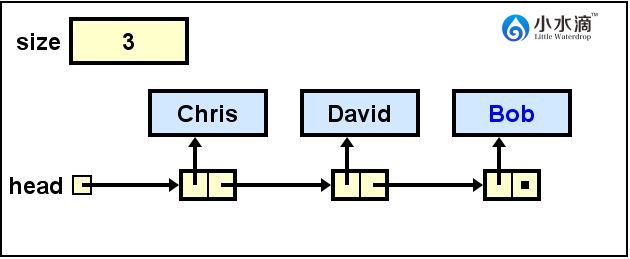
// 删除处于索引2处的节点
nameList.remove(2);
为了表述清晰,此处附上了remove函数的代码。
public void remove(int index) {
// index的范围必须大于等于0且小于size。
if (index < 0 || index >= size)
throw new IllegalArgumentException("Index out of range.");
Node current = head;
Node prev = null; // 因为单向链表仅能单向遍历,我们用prev存储上一个节点的引用。
// 如果要删除的节点是头节点,需要更新head。
if(index == 0) {
head = current.next;
} else {
// 如果要删除的节点不是头节点,则将上一个节点的next更新为被删除节点的next值。
for(int i = 0;i<index;i++) {
prev = current;
current = current.next;
}
prev.next = current.next;
}
size--;
}
因为Java有Garbage Collection机制,没有被引用的对象(object)会被系统自动释放,所以不用像C++一样显式地删除对象。
本操作将上图中处于索引2处的节点(即Adam。Chris在0,David在1,Adam在2,Bob在3)删除。同时将David的next指向Bob,从而保证剩下的节点仍在一个链表之内。
此操作结果如下图所示。
- 单向链表的查找操作(search)
因为在单链表中访问一个节点必须通过其前驱节点来获得该节点的地址,所以当需要在一个链表中查找一个元素值时,必须从头节点开始依次顺序查找直到找到或到达尾节点为止。也就是说,链表查找不支持随机访问,所有查找操作必须从头节点开始查找,依次比较节点。因此查找操作的时间复杂度最好情况为 ,即头节点的元素值等于查找值;最坏情况为 ,即尾节点元素为查找值。因此平均时间复杂度为 。
下面的代码给出的是用于查找String类型元素值的代码。当找到元素时,返回该元素节点的索引值;当未找到元素时,返回-1。
public int search(String s) {
Node current = head;
int index = 0;
while(current != null) {
if(s.equals(current.element)) {
return index;
}
current = current.next;
index++;
}
return -1;
}
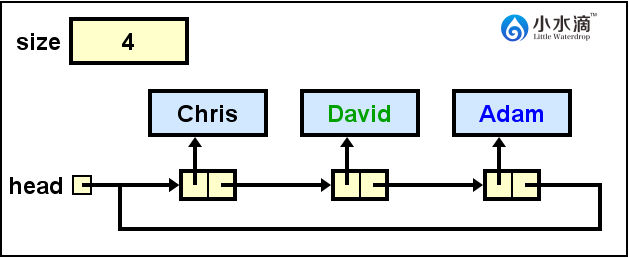
- 循环链表
循环链表与单向链表类似,只是最后一个节点的next不再是null,而是指向该链表的第一个节点(即head指向的节点)。
2. 双向链表(Doubly Linked Lists)
在双向链表中,每个节点都包含当前元素(element),指向下一个节点的引用(next),以及指向上一个节点的引用(prev)。
双向链表的抽象数据类型(ADT)有以下操作:add, remove...
-
双向链表的插入操作
首先,我们先看一个双向链表的节点定义类。
查看和下载源代码public class DoublyLinkedList < E > { private class Node { public E element; public Node next; public Node prev; public Node(E element, Node next, Node prev) { this.element = element; this.next = next; this.prev = prev; } public String toString() { return element.toString(); } } private Node head; private int size; public DoublyLinkedList() { head = null; size = 0; } public int getSize() { return size; } public boolean isEmpty() { return size == 0; } public void add(E element, int index) { if (index < 0 || index > size) throw new IllegalArgumentException("Index out of range."); if (head == null) { head = new Node(element, null, null); } else { if (index == 0) { Node n = new Node(element, head, head.prev); head.prev = n; head = n; } else { Node current = head; for (int i = 0; i < index-1; i++) { current = current.next; } Node n = new Node(element, current.next, current); current.next.prev = n; current.next = n; } } size++; } public void addFirst(E element) { Node n = new Node(element, head, null); if(head != null){ head.prev = n; } head = n; size++; } public void addLast(E element) { Node n = new Node(element, null, null); if(head == null) { head = n; } else { Node current = head; while (current.next != null) { current = current.next; } current.next = n; n.prev = current; } size++; } public void remove(int index) { if (index < 0 || index >= size) throw new IllegalArgumentException("Index out of range."); Node current = head; Node previous = null; if(index == 0) { head = current.next; if(head != null){ head.prev = null; } } else { for(int i = 0; i < index; i++) { previous = current; current = current.next; } if (current == null) { previous.next = null; } else { previous.next = current.next; } if(current != null && current.next != null) { current.next.prev = previous; } } size--; } }如果我们按顺序运行如下的语句。
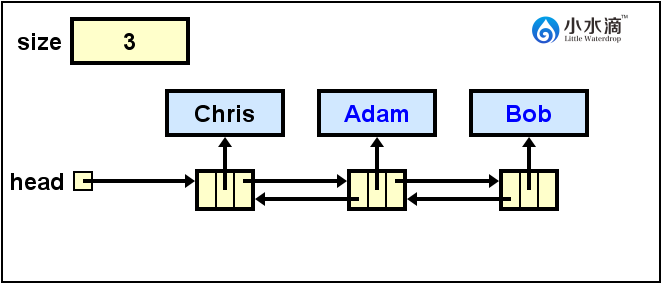
DoublyLinkedList nameList = new DoublyLinkedList<String>(); nameList.addFirst("Adam"); nameList.addLast("Bob"); nameList.addFirst("Chris"); nameList.add("David", 1);每个语句的结果分别如下。双向链表的插入操作与单向链表类似。不过双向链表除了需要更新next还需要更新指向上一个节点的prev。
// 新建一个空的字符串(String)单向链表,将size初始化为0,head初始化为null。该链表所有节点的元素(element)只能是String类型。 LinkedList nameList = new LinkedList<String>();
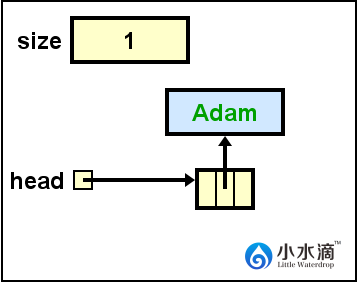
nameList.addFirst("Adam");将“Adam”插入空链表。该节点的next和prev都为null。
此操作结果如下图所示。
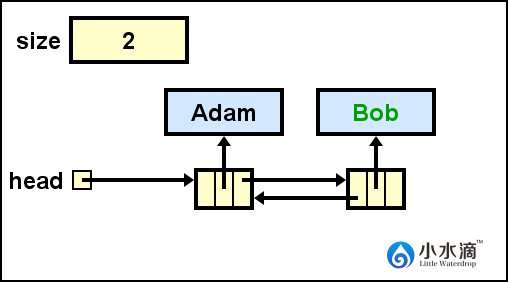
nameList.addLast("Bob");将“Bob”插入有一个节点的链表的表尾。“Adam”节点的next指向“Bob”节点,“Bob”节点的prev指向“Adam”。“Adam”的prev和“Bob”的next都为null。
同样,下图也给出了以下的结果:
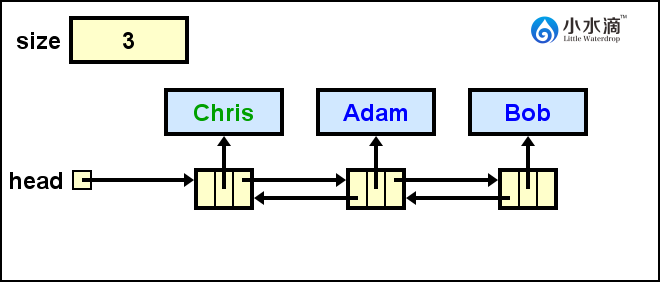
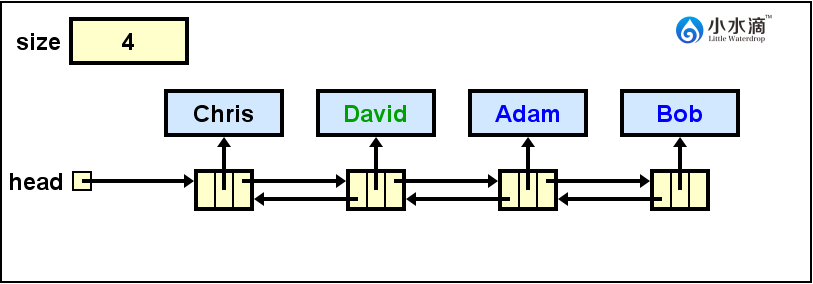
nameList.addFirst("Chris"); nameList.add("David", 1);此操作结果如下图所示。
-
双向链表的删除操作
nameList.remove(1);本操作将上图中处于索引1处的节点(即David。Chris在0,Adam在2,Bob在3)删除。同时将Chris的next指向Adam,Adam的prev指向Chris,从而保证剩下的节点仍在同一个双向链表之内。
此操作结果如下图所示。
3. Java的链表类
关于链表,Java提供了ArrayList和LinkedList两个类。如果只需要大量的随机读取链表且不包括插入和删除操作时,ArrayList的效率更好。当需要在链表开始的位置进行频繁的插入删除操作时,LinkedList的效率更好。程序员应该根据情况进行选择。
-
Java的ArrayList类
下面是一个非常简单的ArrayList的例子。
import java.util.ArrayList; public class NamesArrayList { public static void main(String[] args) { ArrayList<String> names = new ArrayList<String>(); names.add("Adam"); names.add("Bob"); names.add("Chris"); names.add("David"); } }此操作结果如下图所示。
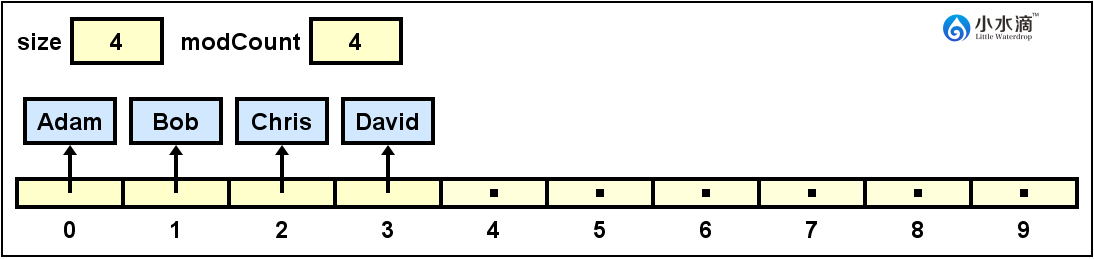
如图所示,如果我们没有给ArrayList的对象指定分配空间,Java会自动将其初始容量设为10。关于ArrayList更多的用法请参见 https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html。
-
Java的LinkedList类
下面是一个非常简单的Java的LinkedList类的例子。
import java.util.LinkedList; public class NamesLinkedList { public static void main(String[] args) { LinkedList<String> names = new LinkedList<String>(); names.add("Adam"); names.add("Bob"); names.add("Chris"); names.add("David"); } }此操作结果如下图所示。
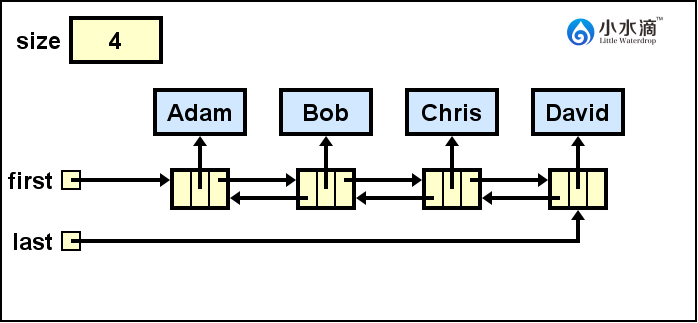
如图所示,Java提供的LinkedList本质上是一个双向链表。
下一章
注册用户登陆后可留言