二叉树(Binary Trees)
1. 树与二叉树
- 树
在图论中,树是一个没有回路的连通图。在计算机的数据结构里,树是一种用来表达有树状结构的数据的数据类型,由有限个节点(node)构成。在本文中,树总是指计算机数据结构中的树。
树有以下术语。
- 父节点(Parent node)
- 子节点(Child node)
- 兄弟节点(Sibling node)
- 根节点(Root node)
我们用一张图来解释以上术语。在下图中,每个节点的元素值为一个整数。
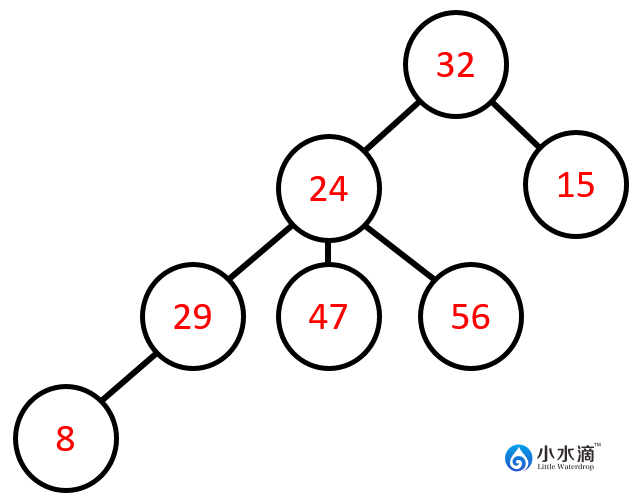
在该图中,32为树的根节点因为它没有父节点。24和15是32的子节点;32是24和15的父节点;24和15互为兄弟节点。同理,24为29,47和56的父节点;29,47,和56为24的子节点;29,47,56互为兄弟节点。因为树不允许有回路,所以一个节点最多只能有一个父节点。8,47,56和15没有子节点。29只有一个子节点。
- 二叉树
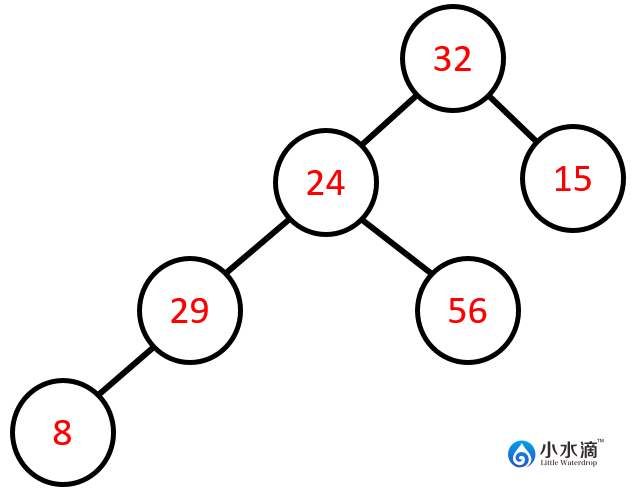
在数据结构中,最常用的树是二叉树,即一个节点最多有两个子节点。上图不是一个二叉树因为24有3个子节点。下图是一个二叉树因为在该图中每个节点的子节点数量都不超过2。
2. 二叉搜索树
二叉搜索树是一类特殊的二叉树。二叉搜索树或者是一棵空树,或者是一棵具有如下性质的二叉树。
- 如果任意节点的左子树不为空,左子树中所有节点的值都小于该节点的值。
- 如果任意节点的右子树不为空,右子树中所有节点的值都大于该节点的值。
- 任意节点的左右子树均为二叉搜索树。
- 所有节点的值都不相等。
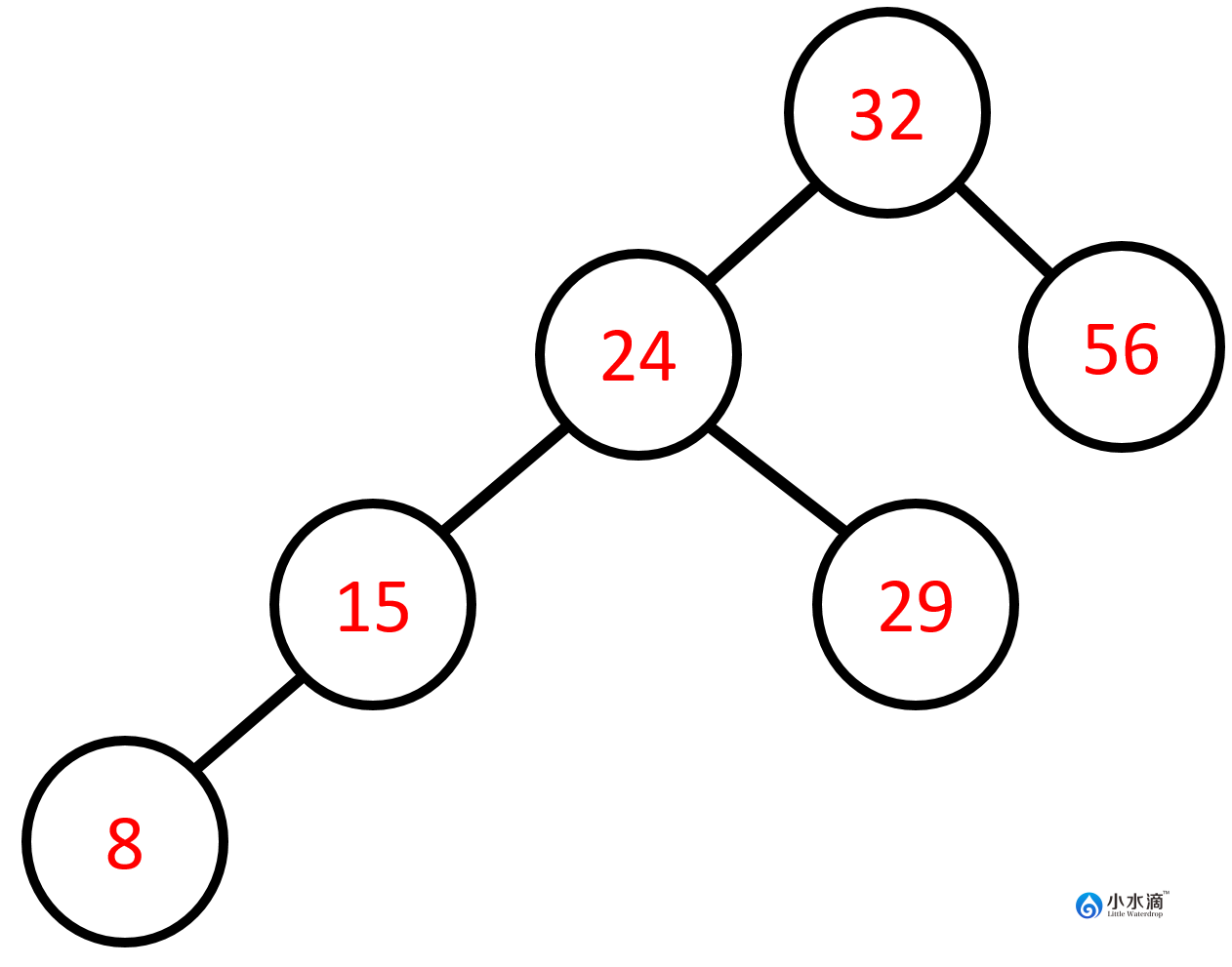
下图是一个二叉搜索树。对于根节点32,所有左子树的节点值(8,15,24,29)都小于32且所有右节点的值(56)都大于32。左右子树也都是二叉搜索树。比如右节点56的左右子树均为空树。根据定义空树也是二叉搜索树,所以以56为根节点的子树也是二叉树。
下面给出二叉搜索树类的代码(还没有insert和search等方法,在文章后面会再讲)。因为不同于链表,栈或者队列,二叉搜索树需要有比较大小的功能 。为了能够比较泛型元素, 我们将泛型E继承Comparable接口,因此二叉搜索树类可以调用compareTo方法来比较泛型变量。
查看和下载源代码public class BinarySearchTree <E extends Comparable<E>> {
Node root; // 二叉树的根节点,初始化为null,即空树。
class Node { // 节点类,是BinarySearchTree类的内部类。
E element; // 节点的元素值。
Node left; // 指向左子树根节点的引用。
Node right; // 指向右子树根节点的引用。
public Node (E e) { // 节点类的构造函数。
element = e;
left = null;
right = null;
}
public String toString() {
return element.toString();
}
}
public BinarySearchTree(){ // BinarySearchTree类的构造函数。
root = null;
}
// 后面再添加二叉搜索树的方法。
}
3. 二叉搜索树的操作
- 插入节点(Insert)
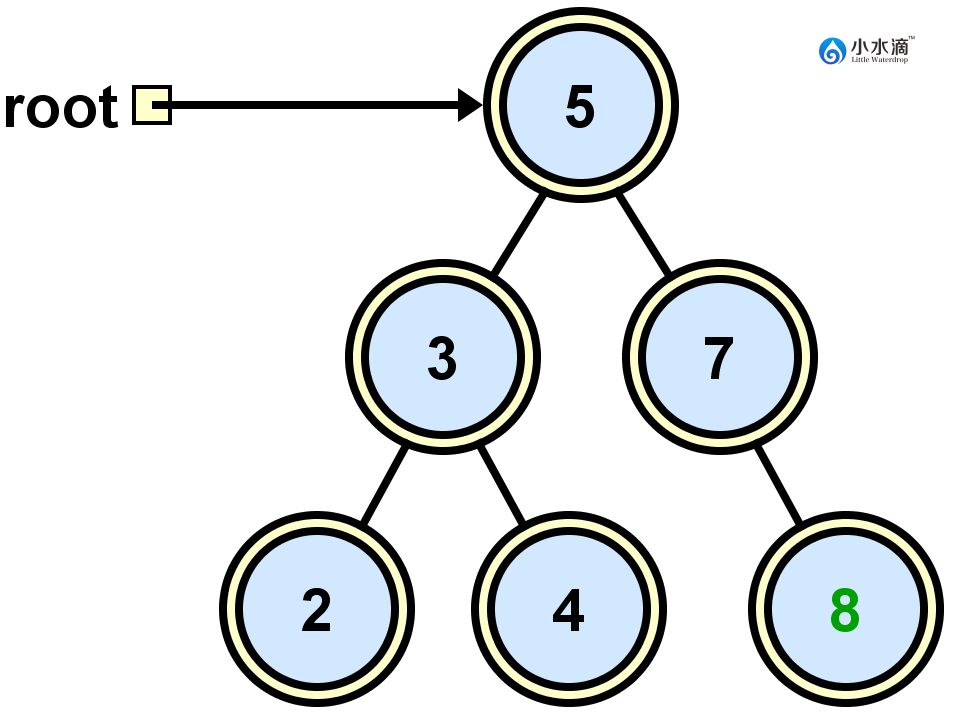
我们将5,3,2,7,4,8六个数字依次插入原本为空的二叉搜索树,过程和最终状态如下图所示。注意不同的插入顺序可能会生成结构不同的二叉搜索树。

插入操作是生成二叉搜索树的关键。下图是插入操作的流程图。
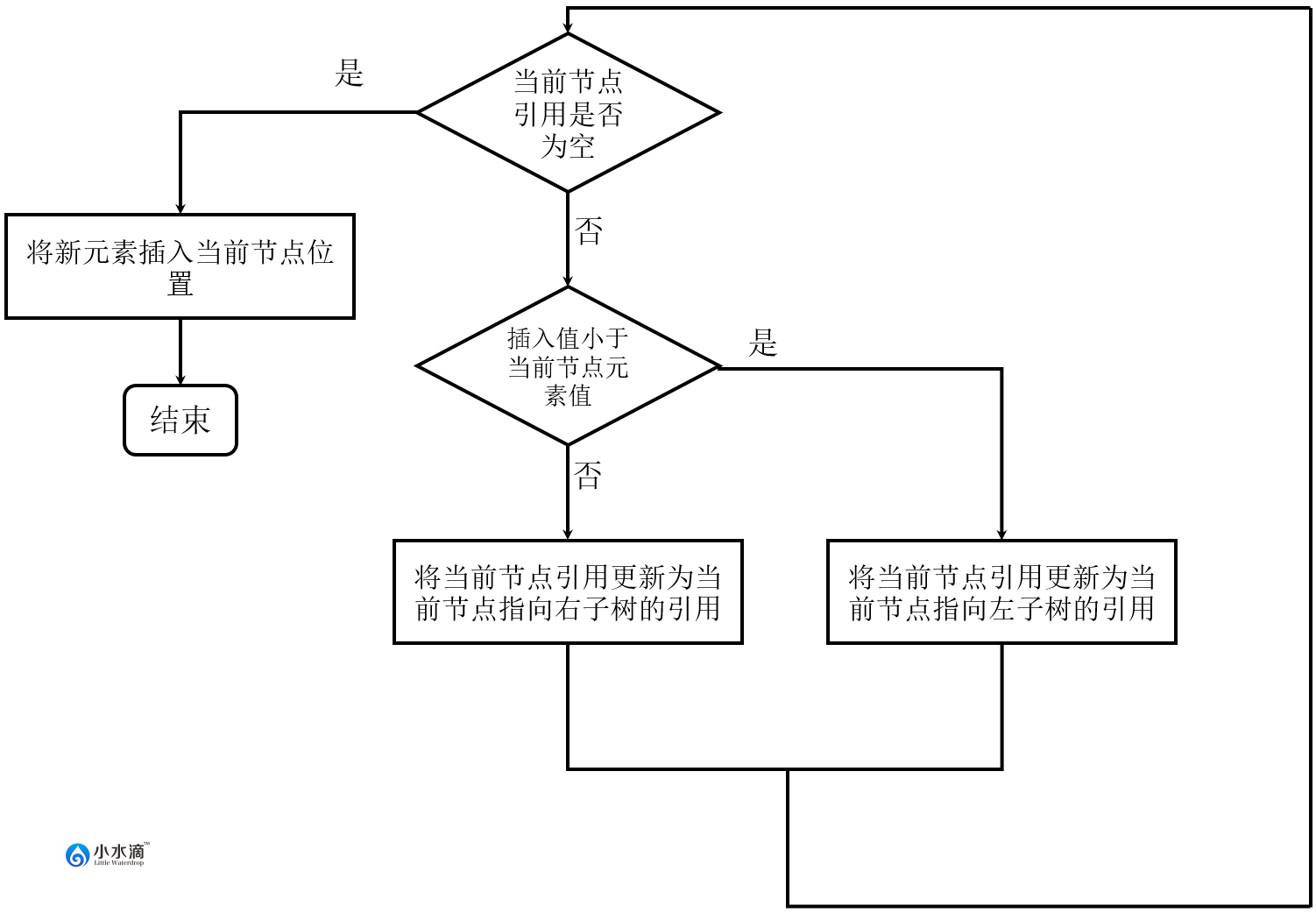
插入操作的方法代码如下。在方法中,用一个while循环从根节点开始来寻找合适的插入点。当前节点初始化为根节点值。当插入的元素值小于当前节点(根节点)的元素值时,进入左子树(当前节点更新为左子树,也就是当前节点左子节点的引用);否则进入右子树(当前节点更新为右子树,也就是当前节点右子节点的引用)。在子树的根节点重复以上操作直到当前节点为空,此处便是新节点应该插入的位置。注意应该保留上一节点的引用和上一步选择的是左子树还是右子树的信息,以便插入新节点。
public void insert(E e) {
Node current = root;
String child = "";
Node prev = null;
while(current != null) {
if(e.compareTo(current.element) < 0) {
prev = current;
child = "Left";
current = current.left;
} else if(e.compareTo(current.element) > 0) {
prev = current;
child = "Right";
current = current.right;
}
}
if(root == null) {
root = new Node(e);
} else if(child.equals("Left")) {
prev.left = new Node(e);
} else {
prev.right = new Node(e);
}
}
插入操作的效率受二叉搜索树的结构影响。当二叉搜索树比较平衡的时候,时间复杂度为O(logN)。当二叉搜索树极端不平衡的时候,时间复杂度为O(N)。N为树中节点的个数。
插入操作也可以用递归实现,以下代码给出了用递归实现的插入操作。需要注意的是尽量避免用递归操作非常不平衡的二叉搜索树。因为不平衡的二叉搜索树高度最高可达N,而平衡的二叉搜索树高度仅为log(N)。过深的二叉搜索树会增加程序调用栈溢出的风险。
private Node insert(E e, Node r) {
if(r == null) {
Node n = new Node(e);
if(root == null) {
root = n;
} else {
r = n;
}
} else if(e.compareTo(r.element) < 0) {
r.left = insert(e, r.left);
} else if(e.compareTo(r.element) > 0) {
r.right = insert(e, r.right);
}
return r;
}
- 搜索(Search)
二叉搜索树的搜索方法和插入方法类似。下图给出了搜索的流程。
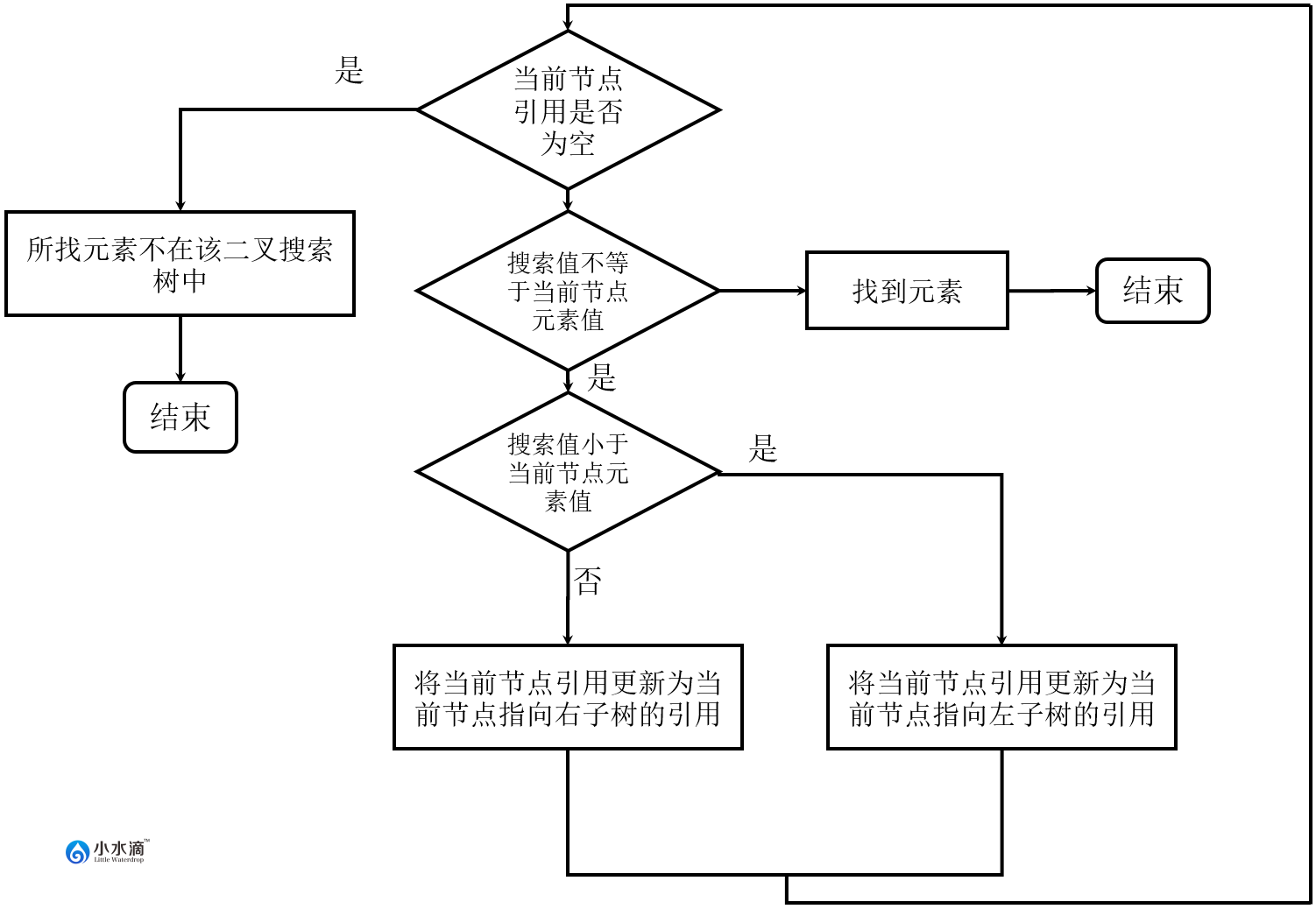
与插入类似,搜索操作也用一个while循环来检查是否当前节点的元素值等于所搜索的元素值。如果相等则找到元素,算法结束返回true;否则根据搜索元素值与当前节点的元素值大小来选择进入左右子树。如果选择的子树为null,则没找到元素(元素不在此二叉搜索树内),算法结束返回false。
public boolean search(E e) {
Node current = root;
while(current != null) {
if(e.compareTo(current.element) == 0) {
return true;
} else if(e.compareTo(current.element) < 0) {
current = current.left;
} else if(e.compareTo(current.element) > 0) {
current = current.right;
}
}
return false;
}
搜索操作的效率也受二叉搜索树的结构影响。当二叉搜索树比较平衡的时候,时间复杂度为O(logN)。当二叉搜索树极端不平衡的时候,时间复杂度为O(N)。N为树中节点的个数。
-
遍历(Traverse)
很多情况下我们需要遍历二叉搜索树,通常遍历二叉树有前序,中序,后序三种顺序。我们用前面生成的二叉搜索树做例子。这三种遍历算法可以非常容易地用递归实现。
-
前序遍历(Pre-Order Traversal)
前序遍历指的是先访问根节点,再访问左右子树的遍历顺序。
public void preOrderTraversal(Node n) { if(n==null) { return; } System.out.println(n.element); preOrderTraversal(n.left); preOrderTraversal(n.right); }前序遍历上图输出的结果是5,3,2,4,7,8。
-
中序遍历(In-Order Traversal))
中序遍历指的是先访问左子树,再访问根节点,最后访问右子树的遍历顺序。
public void inOrderTraversal(Node n) { if(n==null) { return; } inOrderTraversal(n.left); System.out.println(n.element); inOrderTraversal(n.right); }中序遍历上图输出的结果是2,3,4,5,7,8。可以看出,对二叉搜索树的中序遍历实际上是按照元素值的升序顺序。
-
后序遍历(Post-Order Traversal)
后序遍历指的是先访问左右子树,最后访问根节点的遍历顺序。
public void postOrderTraversal(Node n) { if(n==null) { return; } postOrderTraversal(n.left); postOrderTraversal(n.right); System.out.println(n.element); }后序遍历上图输出的结果是2,4,3,8,7,5。
-
上一章
下一章
注册用户登陆后可留言